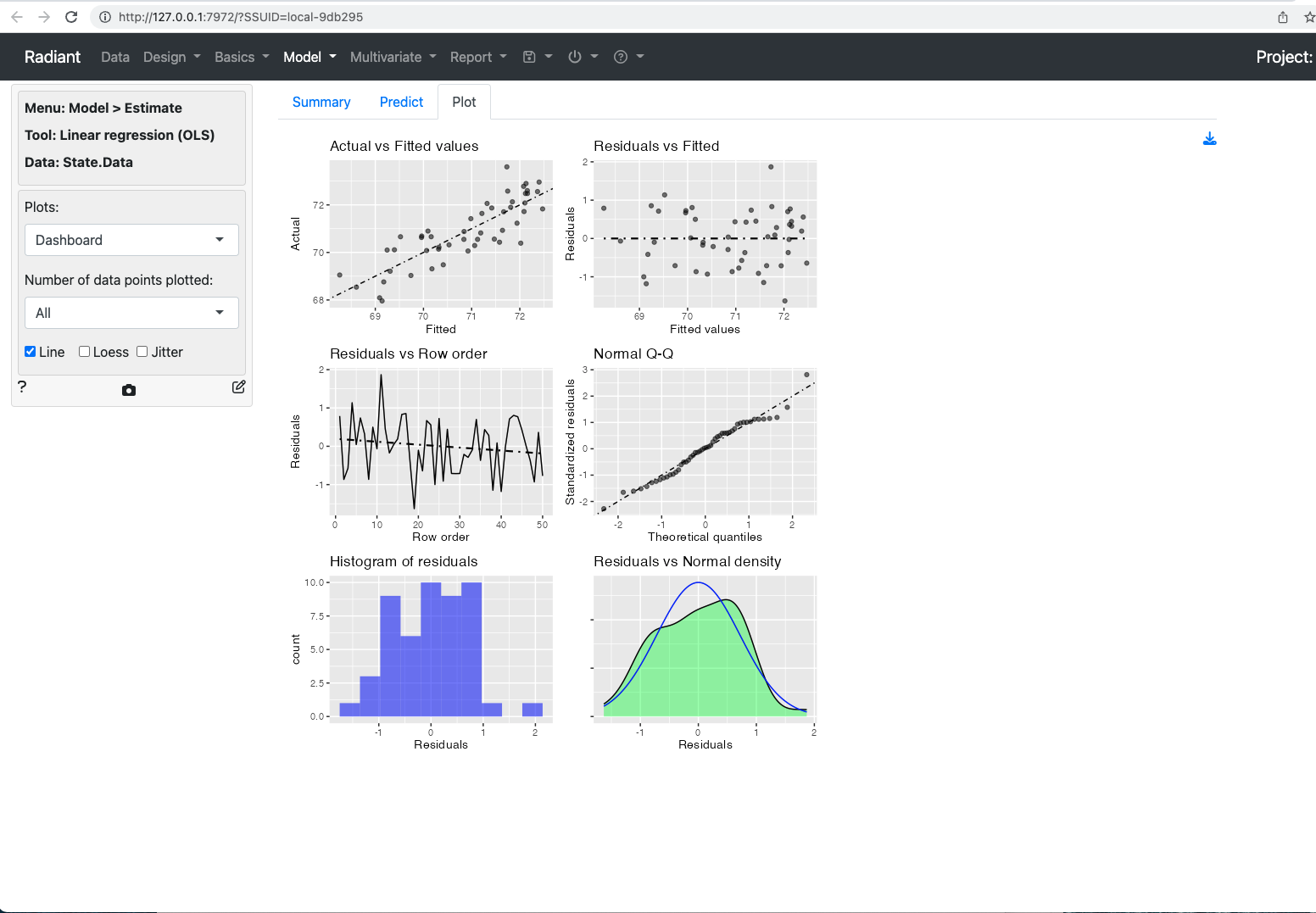
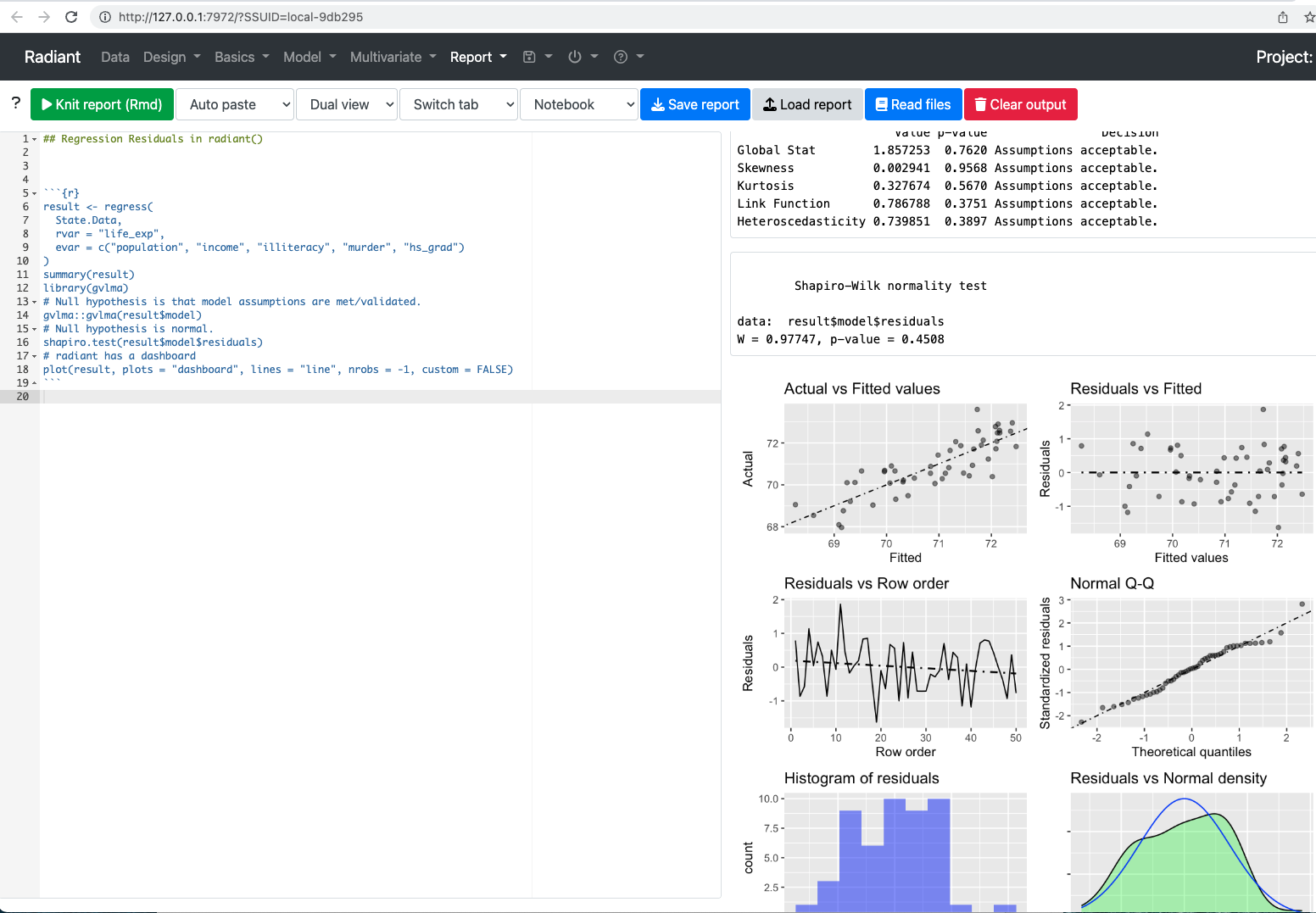
radiant is a very convenient graphical interface for a curated subset of R’s capabilities. In this example, I show how to incorporate additional code into radiant to examine residual normality as a component of validating regression inference.
Let us first begin with some example data. We can read the data off of the github host location for this website.
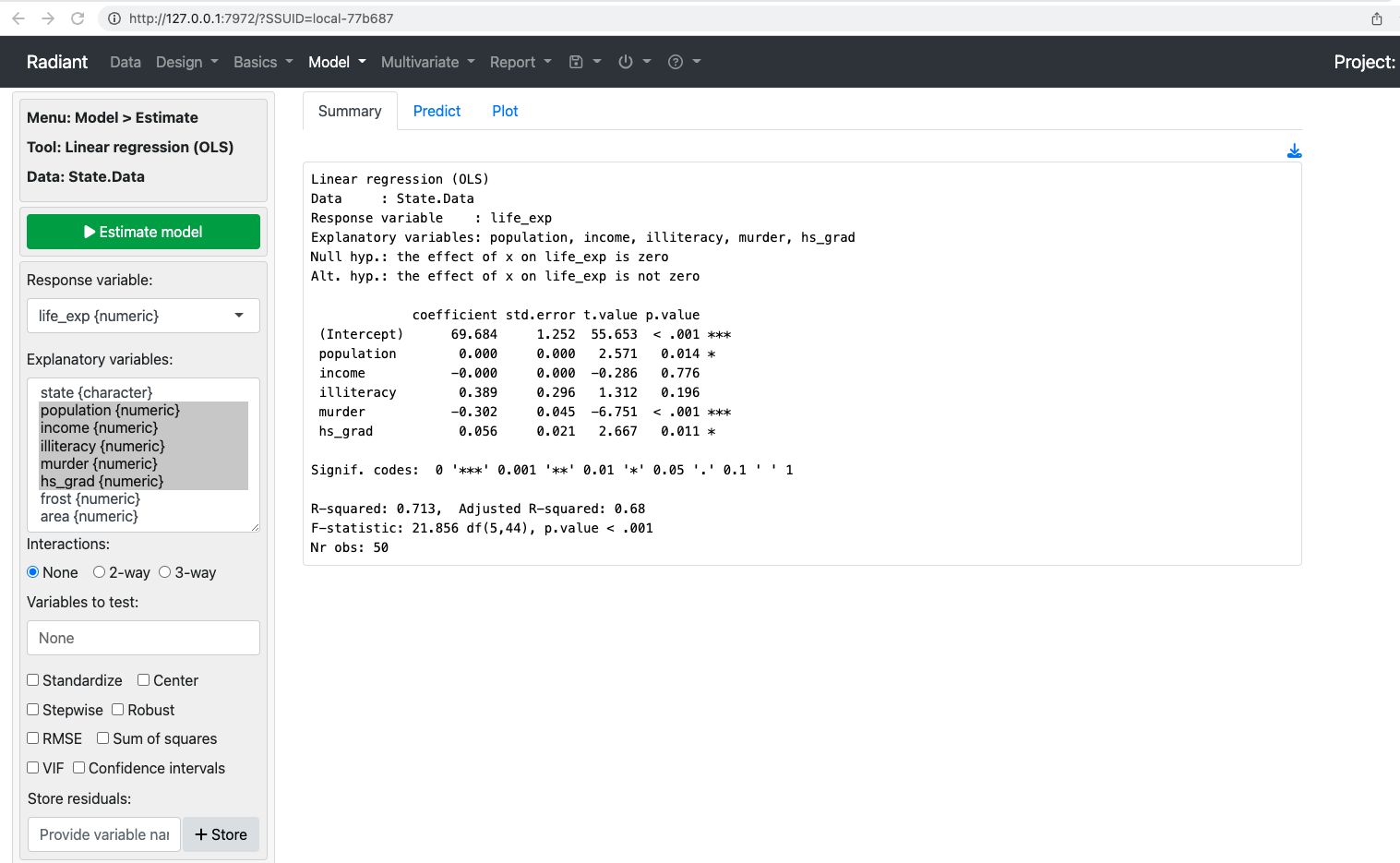
Linear regression (OLS)
Data : State.Data
Response variable : life_exp
Explanatory variables: population, income, illiteracy, murder, hs_grad
Null hyp.: the effect of x on life_exp is zero
Alt. hyp.: the effect of x on life_exp is not zero
coefficient std.error t.value p.value
(Intercept) 69.684 1.252 55.653 < .001 ***
population 0.000 0.000 2.571 0.014 *
income -0.000 0.000 -0.286 0.776
illiteracy 0.389 0.296 1.312 0.196
murder -0.302 0.045 -6.751 < .001 ***
hs_grad 0.056 0.021 2.667 0.011 *
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
R-squared: 0.713, Adjusted R-squared: 0.68
F-statistic: 21.856 df(5,44), p.value < .001
Nr obs: 50
gvlma
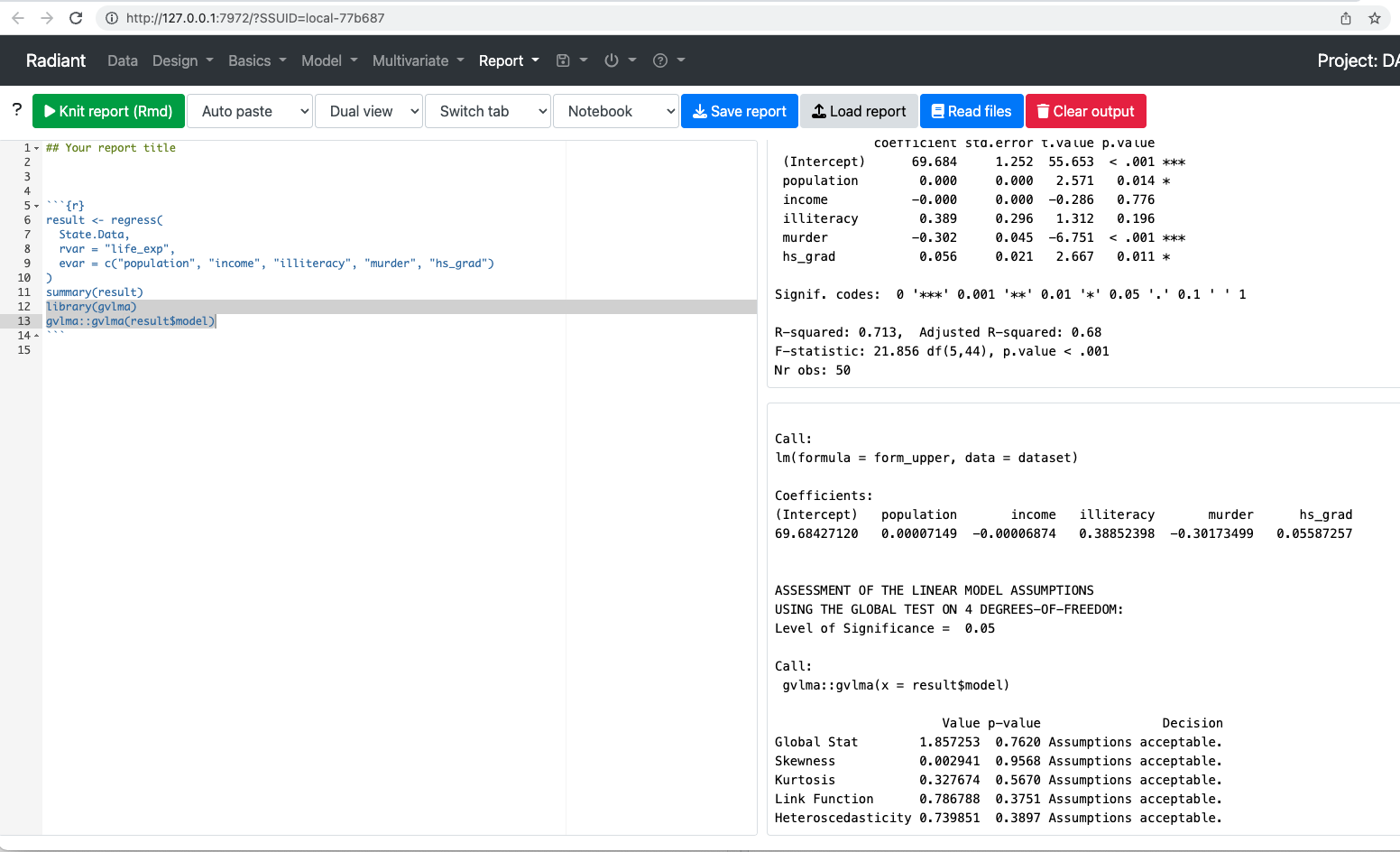
To investigate residuals using radiant, we need to first call a library. The library is gvlma or general validation of linear model assumptions. The necessary command is library(gvlma). Then we want to call gvlma on the model. In this case, that is gvlma(result$model).
gvlma
Once we have added the code, click knit report and the following output should result.
library(gvlma)gvlma::gvlma(result$model)
Call:
lm(formula = form_upper, data = dataset)
Coefficients:
(Intercept) population income illiteracy murder hs_grad
6.968e+01 7.149e-05 -6.874e-05 3.885e-01 -3.017e-01 5.587e-02
ASSESSMENT OF THE LINEAR MODEL ASSUMPTIONS
USING THE GLOBAL TEST ON 4 DEGREES-OF-FREEDOM:
Level of Significance = 0.05
Call:
gvlma::gvlma(x = result$model)
Value p-value Decision
Global Stat 1.857253 0.7620 Assumptions acceptable.
Skewness 0.002941 0.9568 Assumptions acceptable.
Kurtosis 0.327674 0.5670 Assumptions acceptable.
Link Function 0.786788 0.3751 Assumptions acceptable.
Heteroscedasticity 0.739851 0.3897 Assumptions acceptable.
There are reasons to prefer gvlma but we could also use a few other tools. We could deploy a command that requires no additional libraries. With a null hypothesis that residuals are normal and recognizing this is probably best in cases like this with only fifty observations.
shapiro.test(result$model$residuals)
Shapiro-Wilk normality test
data: result$model$residuals
W = 0.97747, p-value = 0.4508
We could also use plotlyreg with the requisite packages installed. I don’t currently like this because it fails to pass the axis names.