Suppose the variable of interest is discrete and takes only two values: yes and no. For example, is a customer satisfied with the outcomes of a given service visit?
For each individual, because the probability of yes (1) \(\pi\) and no (0) 1-\(\pi\) must sum to one, we can write:
\[f(x|\pi) = \pi^{x}(1-\pi)^{1-x}\]
Binomial Distribution
For multiple identical trials, we have the Binomial:
Informal surveys suggest that 15% of Essex shopkeepers will not accept Scottish pounds. There are approximately 200 shops in the general High Street square.
Draw a plot of the distribution of shopkeepers that do not accept Scottish pounds.
How’s that done?
Scots <-data.frame(Potential.Refusers =0:200) %>%mutate(Prob =round(pbinom(Potential.Refusers, size=200, 0.15), digits=4))Scots %>%ggplot() +aes(x=Potential.Refusers, y=Prob) +geom_point() +labs(x="Refusers", y="Prob. of x or Less Refusers") +theme_minimal() -> Plot1Plot1
A Nicer Plot
How’s that done?
library(plotly)p <-ggplotly(Plot1)p
More Questions About Scottish Pounds
What is the probability that 24 or fewer will not accept Scottish pounds?
How’s that done?
pbinom(24, 200, 0.15)
[1] 0.1368173
What is the probability that 25 or more shopkeepers will not accept Scottish pounds?
How’s that done?
1-pbinom(24, 200, 0.15)
[1] 0.8631827
With probability 0.9 [90 percent], XXX or fewer shopkeepers will not accept Scottish pounds.
How’s that done?
qbinom(0.9, 200, 0.15)
[1] 37
Application: The Median is a Binomial with p=0.5
Interestingly, any given observation has a 50-50 chance of being over or under the median. Suppose that I have five datum.
What is the probability that all are under?
How’s that done?
pbinom(0,size=5, p=0.5)
[1] 0.03125
What is the probability that all are over?
How’s that done?
dbinom(5,size=5, p=0.5)
[1] 0.03125
What is the probability that the median is somewhere in between our smallest and largest sampled values?
This is called the Rule of Five by Hubbard in his How to Measure Anything.
Geometric Distributions
How many failures before the first success? Now defined exclusively by \(p\). In each case, (1-p) happens \(k\) times. Then, on the \(k+1^{th}\) try, p. Note 0 failures can happen…
\[Pr(y=k) = (1-p)^{k}p\]
Example: Entrepreneurs
Suppose any startup has a \(p=0.1\) chance of success. How many failures?
Example: Entrepreneurs
Suppose any startup has a \(p=0.1\) chance of success. How many failures for the average/median person?
How’s that done?
qgeom(0.5,0.1)
[1] 6
[Geometric] Plot 1000 random draws of “How many vendors until one refuses my Scottish pounds?”
How many failures before the \(r^{th}\) success? In each case, (1-p) happens \(k\) times. Then, on the \(k+1^{th}\) try, we get our \(r^{th}\) p. Note 0 failures can happen…
\[Pr(y=k) = {k+r-1 \choose r-1}(1-p)^{k}p^{r}\]
Needed Sales
I need to make 5 sales to close for the day. How many potential customers will I have to have to get those five sales when each customer purchases with probability 0.2.
In this last example, I was concerned with sales. I might also want to generate revenues because I know the rough mean and standard deviation of sales. Combining such things together forms the basis of a Monte Carlo simulation.
An Example
Customers arrive at a rate of 7 per hour. You convert customers to buyers at a rate of 85%. Buyers spend, on average 600 dollars with a standard deviation of 150 dollars.
Distributions are how variables and probability relate. They are a graph that we can enter in two ways. From the probability side to solve for values or from values to solve for probability. It is always a function of the graph.
Distributions generally have to be sentences.
The name is a noun but it also has
parameters – verbs – that makes the noun tangible.
Inference of Two Types: Binary and Numeric
Discrete Inference [Binary]
How do we learn from data?
It is probably better posed as, what can we learn from data?.
The Big Idea
Inference
In the most basic form, learning something about data that we do not have from data that we do. In the jargon of statistics, we characterize the probability distribution of some feature of the population of interest from a sample drawn randomly from that population.
Quantities of Interest:
Single Proportion: The probability of some qualitative outcome with appropriate uncertainty.1
Single Mean: The average of some quantitative outcome with appropriate uncertainty.1
The Big Idea
Inference
In the most basic form, learning something about data that we do not have from data that we do. In the jargon of statistics, we characterize the probability distribution of some feature of the population of interest from a sample drawn randomly from that population.
Quantities of Interest:
Compare Proportions: Compare key probabilities across two groups with appropriate uncertainty.2
Compare Means: Compare averages/means across two groups with appropriate uncertainty.1
The Big Idea
Inference
In the most basic form, learning something about data that we do not have from data that we do. In the jargon of statistics, we characterize the probability distribution of some feature of the population of interest from a sample drawn randomly from that population.
Study Planning
Plan studies of adequate size to assess key probabilities of interest.
Inference for Data
Of two forms:
Binary/Qualitative
Quantitative
We will first focus first on the former. But before we do, one new concept.
The standard error
It is the degree of variability of a statistic just as the standard deviation is the variability in data.
The standard error of a proportion is \(\sqrt{\frac{\pi(1-\pi)}{n}}\) while the standard deviation of a binomial sample would be \(\sqrt{n*\pi(1-\pi)}\).
The standard deviation of a sample is \(s\) while the standard error of the mean is \(\frac{s}{\sqrt{n}}\). The average has less variability than the data and it shrinks as n increases.
Let’s think about an election….
Consider election season. The key to modeling the winner of a presidential election is the electoral college in the United States. In almost all cases, this involves a series of binomial variables.
Almost all states award electors for the statewide winner of the election and DC has electoral votes.
We have polls that give us likely vote percentages at the state level. Call it p.win for the probability of winning. We can then deploy rbinom(1000, size=1, p.win) to derive a hypothetical election.
Rinse and repeat to calculate a hypothetical electoral college winner. But how do we calculate p-win?
Is entirely defined by two parameters, \(n\) – the number of subjects – and \(\pi\) – the probability of a positive response. The probability of exactly \(x\) positive responses is given by:
The binomial is the canonical distribution for binary outcomes. Assuming all \(n\) subjects are alike and the outcome occurs with \(\pi\) probability,3 then we must have a sample from a binomial. A binomial with \(n=1\) is known as a Bernoulli trial
Features of the Binomial
Two key features:
Expectation: \(n \cdot \pi\) or number of subjects times probability, \(\pi \textrm{ if } n=1\).
Variance is \(n \cdot \pi \cdot (1 - \pi)\) or \(\pi(1-\pi) \textrm{ if } n=1\) and standard deviation is \(\sqrt{n \cdot \pi \cdot (1 - \pi)}\) or \(\sqrt{\pi(1-\pi)} \textrm{ if } n=1\).
What is the probability of being admitted to UC Berkeley Graduate School?4
. . .
I have three variables:
Admitted or not
Gender
The department an applicant applied to.
Admission is the key.
How’s that done?
library(janitor) #<<UCBTab <-data.frame(UCBAdmissions) %>% reshape::untable(., .$Freq) %>%select(-Freq)UCBTab %>%tabyl(Admit) # Could also use UCBTab %$% table(Admit)
Admit n percent
Admitted 1755 0.388
Rejected 2771 0.612
The proportion is denoted as \(\hat{p}\). We can also do this with table.
Exact binomial test
data: .
number of successes = 1755, number of trials = 4526, p-value
<2e-16
alternative hypothesis: true probability of success is not equal to 0.5
90 percent confidence interval:
0.376 0.400
sample estimates:
probability of success
0.388
With 90% probability, now often referred to as 90% confidence to avoid using the word probability twice, the probability of being admitted ranges between 0.3758 and 0.3998.
Exact binomial test
data: .
number of successes = 1755, number of trials = 4526, p-value
<2e-16
alternative hypothesis: true probability of success is not equal to 0.5
90 percent confidence interval:
0.376 0.400
sample estimates:
probability of success
0.388
Binomial.Search <-data.frame(x =seq(0.33, 0.43, by =0.001)) %>%mutate(Too.Low =pbinom(1755, 1755+2771, x), Too.High =1-pbinom(1754,1755+2771, x))Binomial.Search %>%pivot_longer(cols =c(Too.Low, Too.High)) %>%ggplot(., aes(x = x, y = value, color = name)) +geom_line() +geom_hline(aes(yintercept =0.05)) +geom_hline(aes(yintercept =0.95)) +geom_vline(data = Plot.Me, aes(xintercept = .),linetype =3) +labs(title ="Using the Binomial to Search", color ="Greater/Lesser",x =expression(pi), y ="Probability")
A Third Way: The normal approximation
As long as \(n\) and \(\pi\) are sufficiently large, we can approximate this with a normal distribution. This will also prove handy for a related reason.
As long as \(n*\pi\) > 10, we can write that a standard normal \(z\) describes the distribution of \(\pi\), given \(n\) – the sample size and \(\hat{p}\) – the proportion of yes’s/true’s in the sample.
\(R\) implements this in prop.test. By default, R implements a modified version that corrects for discreteness/continuity. To get the above formula exactly, prop.test(table, correct=FALSE).
A first look at hypotheses
\[ z = \frac{\hat{p} - \pi}{\sqrt{\frac{\pi(1-\pi)}{n}}} \]
With some proportion calculated from data \(\hat{p}\) and some claim about \(\pi\) – hereafter called an hypothesis – we can use \(z\) to calculate/evaluate the claim. These claims are hypothetical values of \(\pi\). They can be evaluated against a specific alternative considered in three ways:
two-sided, that is \(\pi = value\) against not equal.
\(\pi \geq value\) against something smaller.
\(\pi \leq value\) against something greater.
In the first case, either much bigger or much smaller values could be evidence against equal. The second and third cases are always about smaller and bigger; they are one-sided.
Just as \(z\) has metric standard deviations now referred to as standard errors of the proportion, the z here will measure where the data fall with respect to the hypothetical \(\pi\).
With z sufficiently large, and in the proper direction, our hypothetical \(\pi\) becomes unlikely given the evidence and should be dismissed.
Three hypothesis tests
How’s that done?
(Z.ALL <- (0.3877596-0.5)/(sqrt(0.5^2/4526))) # Calculate z
[1] -15.1
The estimate is 15.1 standard errors below the hypothesized value.
Two Sided
\(\pi = 0.5\) against \(\pi \neq 0.5\).
How’s that done?
pnorm(-abs(Z.ALL)) + (1-pnorm(abs(Z.ALL)))
[1] 7.85e-52
Any \(|z| > 1.64\) – probability 0.05 above and below – is sufficient to dispense with the hypothesis.
1-sample proportions test without continuity correction
data: table(UCBTab$Admit), null probability 0.5
X-squared = 228, df = 1, p-value <2e-16
alternative hypothesis: true p is not equal to 0.5
90 percent confidence interval:
0.376 0.400
sample estimates:
p
0.388
\(R\) reports the result as \(z^2\) not \(z\) which is \(\chi^2\) not normal; we can obtain the \(z\) by taking a square root: \[\sqrt{228.08} \approx 15.1 \]
This approximation yields an estimate of \(\pi\), with 90% confidence, that ranges between 0.376 and 0.4.
A Cool Consequence of Normal
The formal equation defines:
\[ z = \frac{\hat{p} - \pi}{\sqrt{\frac{\pi(1-\pi)}{n}}} \]
Some language:
Margin of error is \(\hat{p} - \pi\). [MOE]
Confidence: the probability coverage given z [two-sided].
We need a guess at the true \(\pi\) because variance/std. dev. depend on \(\pi\). 0.5 is common because it maximizes the variance; we will have enough no matter what the true value.
Algebra allows us to solve for \(n\).
\[ n = \frac{z^2 \cdot \pi(1-\pi)}{(\hat{p} - \pi)^2} \]
Example
Estimate the probability of supporting an initiative to within 0.03 with 95% confidence. Assume that the probability is 0.5 [it maximizes the variance and renders a conservative estimate – an upper bound on the sample size]
What is our estimate of \(\pi\) with 90% confidence?
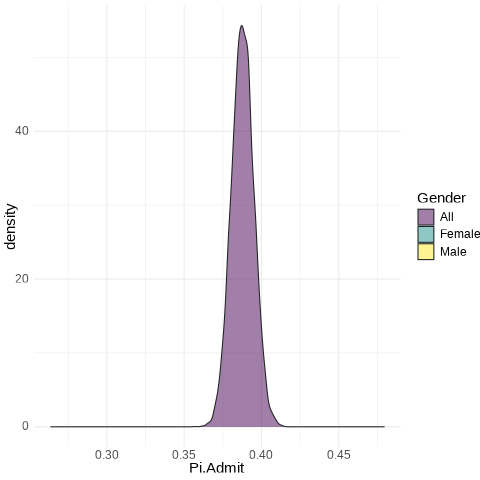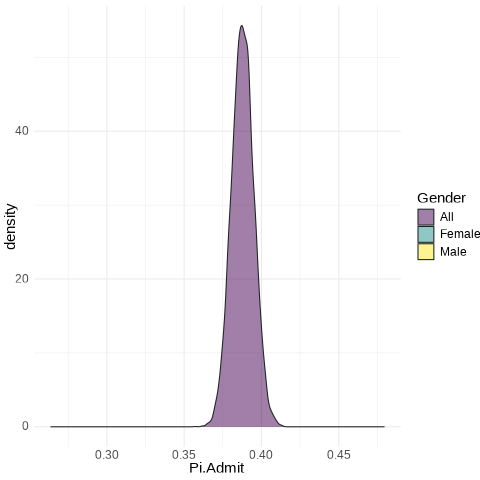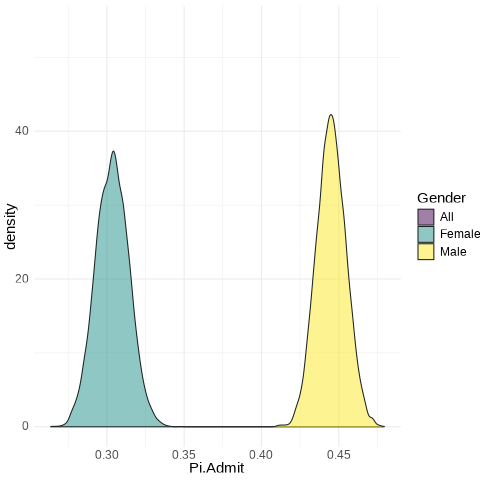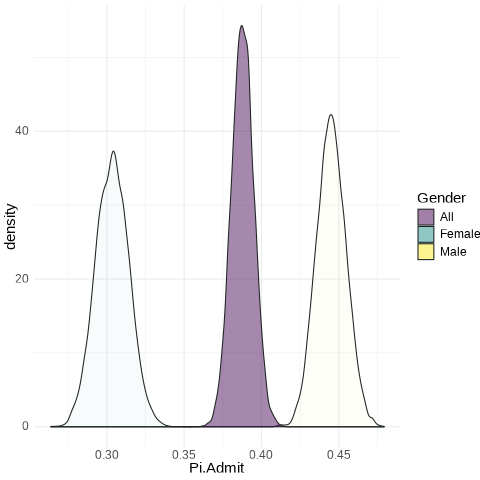
The probability of admission ranges from 0.376 to 0.4.
If we wish to express this using the normal approximation, a central interval is the observed proportion plus/minus \(z\) times the standard error of the proportion – \[ SE(\hat{p}) = \sqrt{\frac{\hat{p}(1-\hat{p})}{n}} \] NB: The sample value replaces our assumed true value because \(\pi\) is to be solved for. For 90%, the probability of admissions ranges from
Exact binomial test
data: .
number of successes = 1198, number of trials = 2691, p-value =
0.00000001
alternative hypothesis: true probability of success is not equal to 0.5
90 percent confidence interval:
0.429 0.461
sample estimates:
probability of success
0.445
The probability of being admitted, conditional on being Male, ranges from 0.43 to 0.46 with 90% confidence.
Exact binomial test
data: .
number of successes = 557, number of trials = 1835, p-value <2e-16
alternative hypothesis: true probability of success is not equal to 0.5
90 percent confidence interval:
0.286 0.322
sample estimates:
probability of success
0.304
The probability of being of Admitted, given a Female, ranges from 0.286 to 0.322 with 90% confidence.
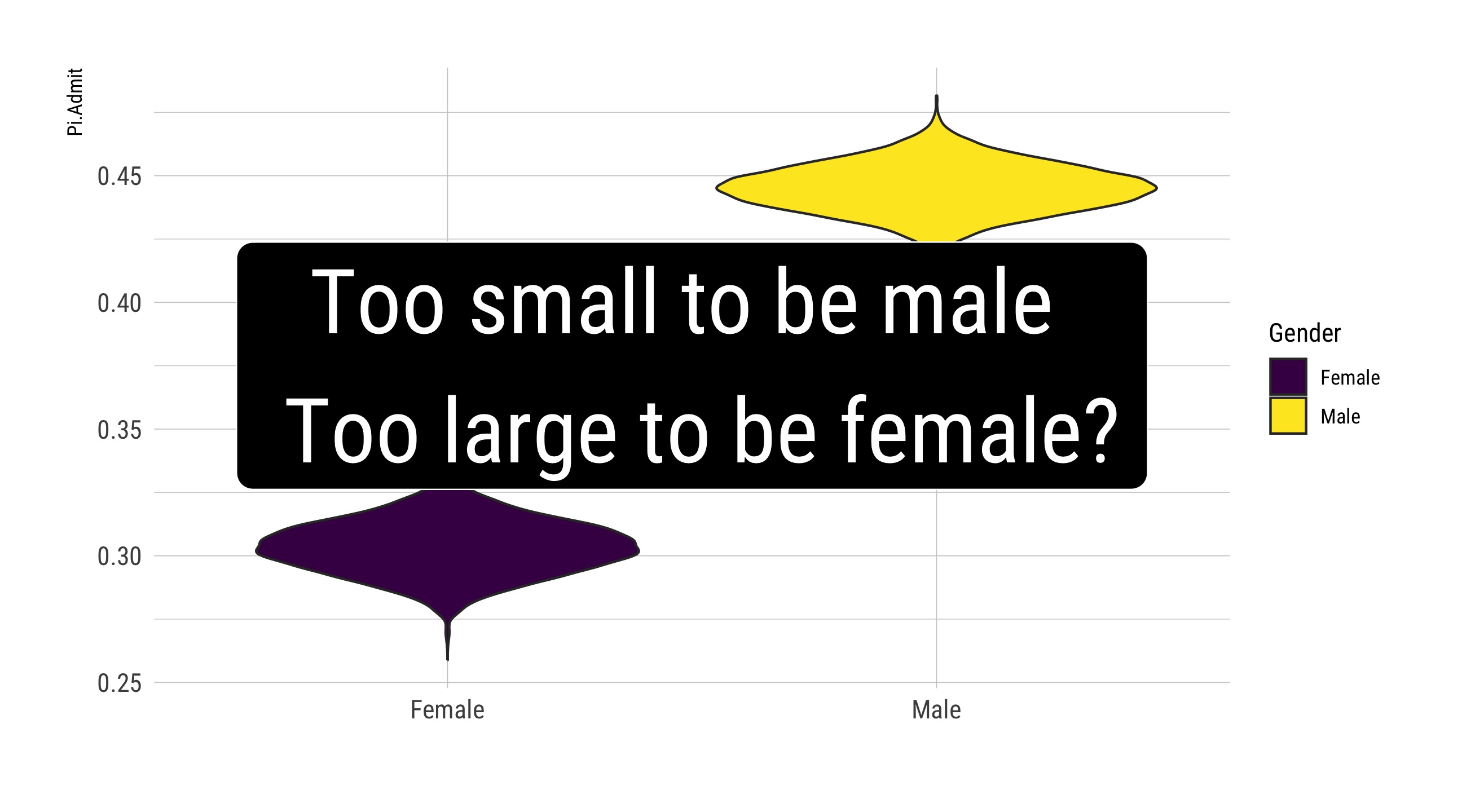
Female: from 0.286 to 0.322
Male: from 0.43 to 0.46
All: from 0.3758 to 0.3998
A Key Visual
How’s that done?
UCB.Pi <-bind_rows(UCBTF.Pi, UCBTM.Pi)UCB.Pi %>%ggplot(., aes(x = Gender, y = Pi.Admit, fill = Gender)) +geom_violin() +geom_label(aes(x =1.5, y =0.375), label ="Too small to be male \n Too large to be female?",size =14, fill ="black", color ="white", inherit.aes =FALSE) +guides(size ="none") +labs(x ="") +scale_fill_viridis_d()
2-sample test for equality of proportions without continuity
correction
data: .
X-squared = 92, df = 1, p-value <2e-16
alternative hypothesis: two.sided
90 percent confidence interval:
0.118 0.165
sample estimates:
prop 1 prop 2
0.445 0.304
With 90% confidence, a Female is 0.118 to 0.165 [0.1416] less likely to be admitted.
The Standard Error of the Difference
Following something akin to the FOIL method, we can show that the variance of a difference in two random variables is the sum of the variances minus twice the covariance between them.
\[Var(X - Y) = Var(X) + Var(Y) - 2*Cov(X,Y) \]
If we assume [or recognize it is generally unknownable] that the male and female samples are independent, the covariance is zero, and the variance of the difference is simply the sum of the variance for male and female, respectively, and zero covariance.
The sum of \(k\) squared standard normal (z or Normal(0,1)) variates has a \(\chi^2\) distribution with \(k\) degrees of freedom. Two sample tests of proportions can be reported using the chi-square metric as well. \(R\)’s prop.test does this by default.