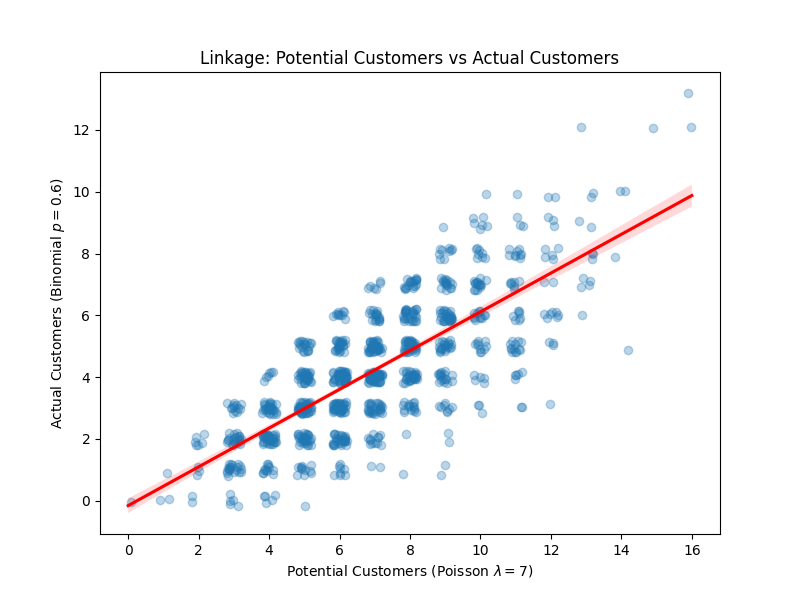
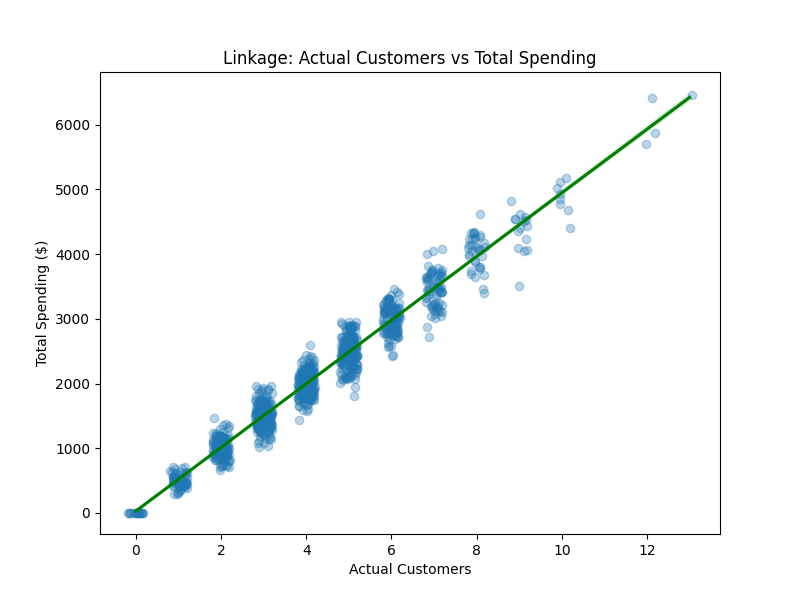
How’s that done?
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# Set seed for reproducibility
np.random.seed(42)
# Parameters
iterations = 1000
lambda_poisson = 7
p_purchase = 0.6
mean_spending = 500
std_spending = 100
results = []
for i in range(iterations):
# Step 1: Sample Potential Customers
potential_customers = np.random.poisson(lambda_poisson)
# Step 2: Sample Actual Customers (Binomial)
# Alternatively: check each potential customer with a 0.6 prob
actual_customers = np.random.binomial(n=potential_customers, p=p_purchase)
# Step 3: Sample Spending for each customer
if actual_customers > 0:
individual_spendings = np.random.normal(mean_spending, std_spending, actual_customers)
total_spending = np.sum(individual_spendings)
else:
total_spending = 0.0
results.append({
'Iteration': i + 1,
'Potential_Customers': potential_customers,
'Actual_Customers': actual_customers,
'Total_Spending': total_spending
})
df = pd.DataFrame(results)
# Save to CSV
df.to_csv('monte_carlo_simulation_results.csv', index=False)
# Summary statistics
summary_stats = df.describe()
print(summary_stats) Iteration Potential_Customers Actual_Customers Total_Spending
count 1000.000000 1000.000000 1000.000000 1000.000000
mean 500.500000 6.940000 4.192000 2091.394737
std 288.819436 2.492913 2.063345 1035.160073
min 1.000000 0.000000 0.000000 0.000000
25% 250.750000 5.000000 3.000000 1346.837689
50% 500.500000 7.000000 4.000000 2013.612058
75% 750.250000 9.000000 5.000000 2773.369027
max 1000.000000 16.000000 13.000000 6465.587864How’s that done?
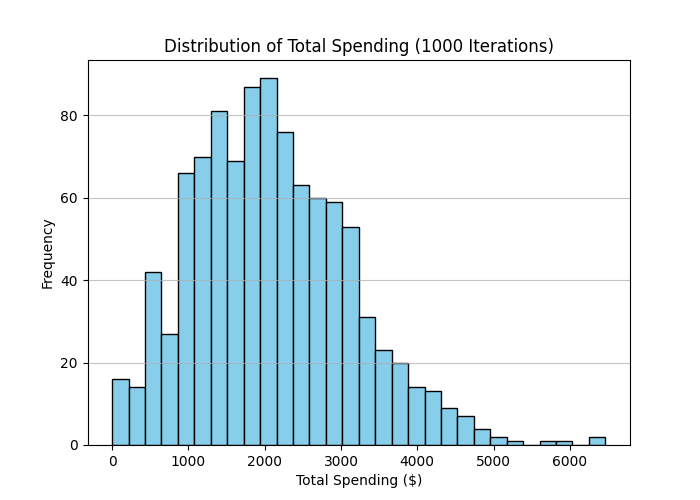
# Plotting the distribution of Total Spending
plt.hist(df['Total_Spending'], bins=30, color='skyblue', edgecolor='black')
plt.title('Distribution of Total Spending (1000 Iterations)')
plt.xlabel('Total Spending ($)')
plt.ylabel('Frequency')
plt.grid(axis='y', alpha=0.75)
plt.savefig('total_spending_distribution.png')
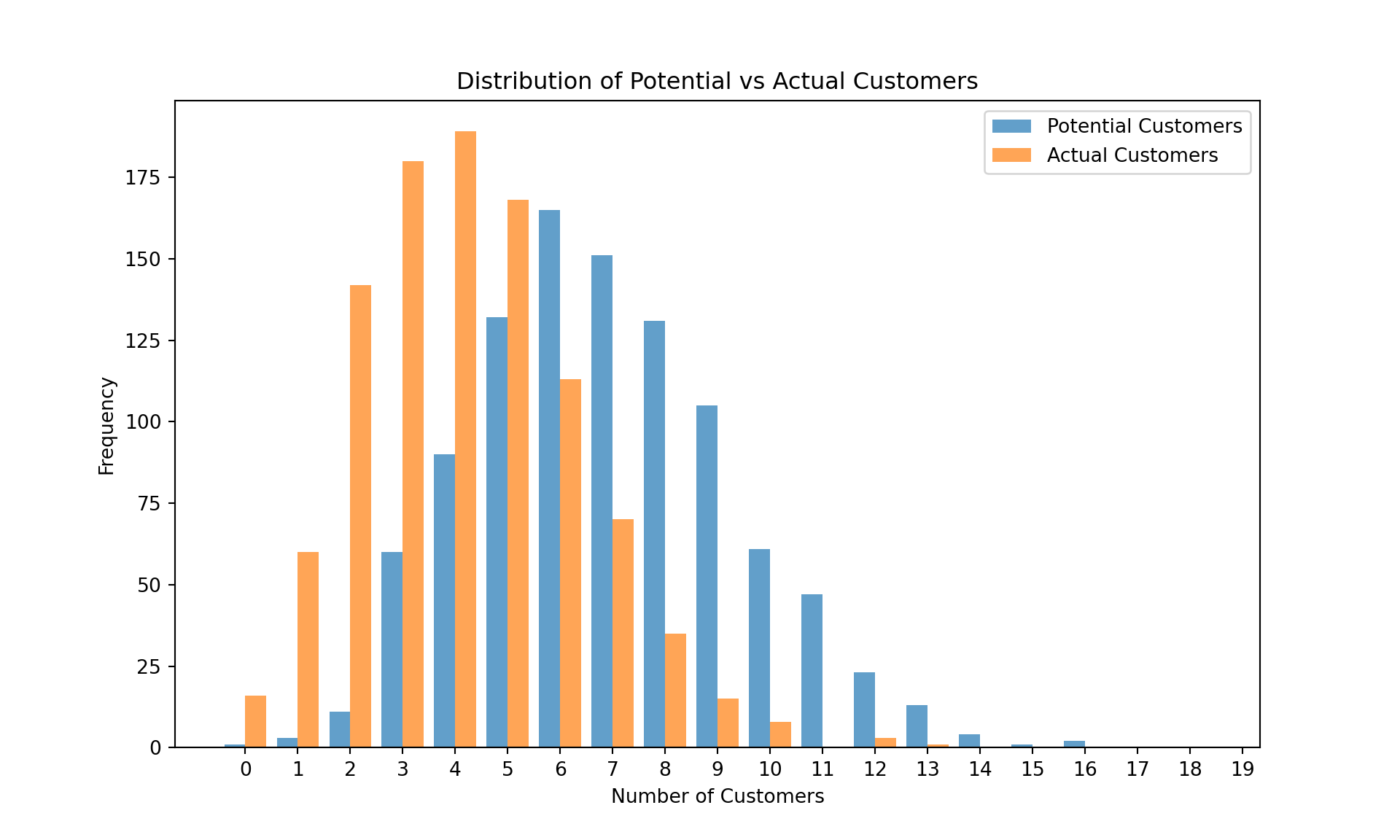
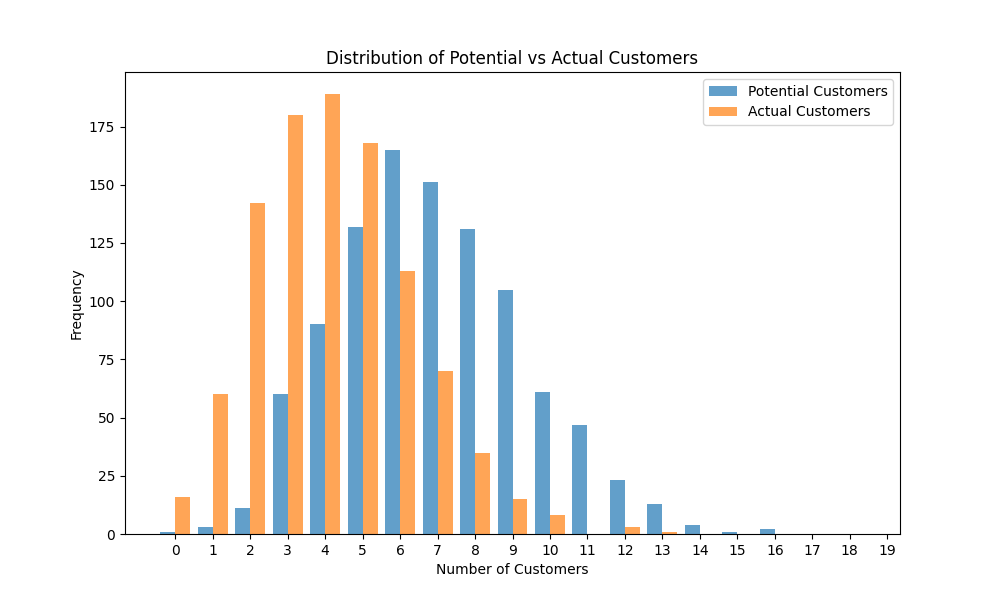
# Plotting Potential vs Actual Customers
plt.clf()
plt.figure(figsize=(10, 6))
plt.hist([df['Potential_Customers'], df['Actual_Customers']], label=['Potential Customers', 'Actual Customers'], bins=np.arange(0, 20) - 0.5, alpha=0.7)(array([[ 1., 3., 11., 60., 90., 132., 165., 151., 131., 105., 61.,
47., 23., 13., 4., 1., 2., 0., 0.],
[ 16., 60., 142., 180., 189., 168., 113., 70., 35., 15., 8.,
0., 3., 1., 0., 0., 0., 0., 0.]]), array([-0.5, 0.5, 1.5, 2.5, 3.5, 4.5, 5.5, 6.5, 7.5, 8.5, 9.5,
10.5, 11.5, 12.5, 13.5, 14.5, 15.5, 16.5, 17.5, 18.5]), <a list of 2 BarContainer objects>)How’s that done?
plt.title('Distribution of Potential vs Actual Customers')
plt.xlabel('Number of Customers')
plt.ylabel('Frequency')
plt.legend()
plt.xticks(range(0, 20))([<matplotlib.axis.XTick object at 0x11a0a2fd0>, <matplotlib.axis.XTick object at 0x11a1f87d0>, <matplotlib.axis.XTick object at 0x11a1f8b90>, <matplotlib.axis.XTick object at 0x11a1f8f50>, <matplotlib.axis.XTick object at 0x11a1f9310>, <matplotlib.axis.XTick object at 0x11a1f96d0>, <matplotlib.axis.XTick object at 0x11a1f9a90>, <matplotlib.axis.XTick object at 0x11a1f9e50>, <matplotlib.axis.XTick object at 0x11a1fa210>, <matplotlib.axis.XTick object at 0x11a1fa5d0>, <matplotlib.axis.XTick object at 0x11a1fa990>, <matplotlib.axis.XTick object at 0x11a1fad50>, <matplotlib.axis.XTick object at 0x11a1fb110>, <matplotlib.axis.XTick object at 0x11a1fb4d0>, <matplotlib.axis.XTick object at 0x11a1fb890>, <matplotlib.axis.XTick object at 0x11a1fbc50>, <matplotlib.axis.XTick object at 0x11a234050>, <matplotlib.axis.XTick object at 0x11a234410>, <matplotlib.axis.XTick object at 0x11a2347d0>, <matplotlib.axis.XTick object at 0x11a234b90>], [Text(0, 0, '0'), Text(1, 0, '1'), Text(2, 0, '2'), Text(3, 0, '3'), Text(4, 0, '4'), Text(5, 0, '5'), Text(6, 0, '6'), Text(7, 0, '7'), Text(8, 0, '8'), Text(9, 0, '9'), Text(10, 0, '10'), Text(11, 0, '11'), Text(12, 0, '12'), Text(13, 0, '13'), Text(14, 0, '14'), Text(15, 0, '15'), Text(16, 0, '16'), Text(17, 0, '17'), Text(18, 0, '18'), Text(19, 0, '19')])How’s that done?
plt.savefig('customer_counts.png')