Placeholder (you should not see this)
Question 1
- A machine produces defective parts with probabilities that depend on the state of repair. If the machine is in good working order, it produces defective parts with probability 0.02. If the machine is wearing down, it produces defective parts 10% of the time. If the machine is in need of repairs, then it produces defective parts 30% of the time. The probability that the machine is in good working order is 0.8; the probability that the machine is wearing down or in need of repair is 0.1 (for each).
- Compute the probability that a randomly selected completed part is defective. NB: There is no difference in the rate of production among the repair states, only a difference in the number of defects.
There is a 0.02*0.8 + 0.1*0.1 + 0.1*0.3 = 0.056 total probability of errors.
- A factory consists of three machines. One machine is in good working order. One machine is wearing down and one is in need of repairs. All three machines produce at the same rate. You are given a defective part; what is the probability that each machine produced it?
Good working order is 0.02, wearing down is 0.1, in need of repairs is 0.3. Each, times one-third yields 0.14. So P(INR) = 5/7; P(WD) = 5/21; P(GWO)= 1/21.
Question 2
- The Monty Hall problem is fashioned after an old television game show. You are a contestant and you are faced with three doors, labeled A, B, and C. Behind one of the three doors is a new car. The other two doors contain goats. The drama is created by a choice you will make though you actually make two. First, you choose a door. After you have chosen, Monty will show you one of the two doors that you did not choose and there will be a goat behind that door. At this point is the drama, will you keep your original choice or will you switch to the remaining unopened door? To solve the problem, provide a decision-tree depicting the choices and outcomes. Is it better to stick with your choice or to switch?
It is better to switch. Monty shows you a door with a goat, no matter what. So the original probability that you are correct [stay] is 1/3 while the probability that you are correct if you switch must be 2/3. The key to the tree is that Monty randomizes the door he shows you only if you were initially correct.
Question 3
- For a variety of reasons, various forms of drug screening are utilized by employers throughout the United States. Here we confront a decision over pre-employment screening. Suppose a test is 99% accurate for actual Users of a given drug and 95% accurate for non-Users of the same substance. Moreover, we know that Users make up 10% of the population. How we know these things is an appropriate question and in some cases, the answers may not be all that satisfying.
- What is the probability of a positive test for a random individual with no knowledge of their usage status?
0.99*0.1 + 0.05*0.9 = 0.099+0.045=0.144.. 99 percent of the 10 percent users and 5 percent of the 90 percent non-users.
- What is the probability of a positive test for a random individual with no knowledge of their usage status?
- If someone tests positive, what is the probability that they are an actual user of the drug? This is 0.099 above and it is taken as a percentage of the total, 0.144. This is 0.6875.
- Is this test useful as a pre-employment screen? Assuming that the employee is chosen for reasons unrelated to this, what are the costs and benefits? Just over one-third of the positives are actual users so it is not great but it is better than nothing.
Question 4
- One of the most important metrics for Facebook is something known as a Markov matrix – a matrix linking current and past realizations of some outcome. Their particular interest is in the use of an experimental Facebook shopping platform per month. Consider the following subset of data for a recent month. There are a few features of this platform that make it unlike most others; it is by invitation only so the size of both the yes and no populations are actually known (this is almost never true in any precise way).
- What is the conditional probability of being a current user of the shopping platform given that you previously used the platform? There were 184,000 users and 164,000 remain; the probability is 0.8913.
- What is the rate of user loss – the conditional probability of becoming a non-user of the platform given use in the prior period? One minus the above; this probability is 0.1087.
- Is the platform growing or shrinking? How would you measure that? Explain/defend your answer? The platform is growing; they lost 20,000 but gained 24,000.
- What is the probability of not being a user of the platform in the current period? 1972000 of 2160000 is 0.913.
Data Examples
Two exercises based on data are a part of this review.
Disability Expenditures
The document can be directly linked to.. The quarto rendering here is not perfect.
The document can be directly linked to..
The data set presented is designed to represent a sample of 1,000 DDS consumers (which provides a 95% confidence interval with a margin of error of \(\pm\) 3.5% for this 250,000 consumer population). The data set includes six variables (i.e., fields) which are: ID, age cohort/age (binned/unbinned), gender, expenditures, and ethnicity. NB: The data set originated from DDS’s Client Master File. In order to remain in compliance with California State Legislation, the data have been altered to protect the rights and privacy of specific individual consumers. The provided data set is based on actual attributes of consumers.
ID is the unique identification code for each consumer. It is similar to a social security number and used for identification purposes.
Age cohort/age is a key variable in the case exercise. While age is a legal basis for discrimination in many situations, age is not an attribute that would be considered in a discrimination claim for this particular population. The purpose of providing funds to those with developmental disabilities is to help them live like those without disabilities. As consumers get older, their financial needs increase as they move out of their parent’s home, etc. Therefore, it is expected that expenditures for older consumers will be higher than for the younger consumers.
We have included both binned (Age cohort) and unbinned (Age) variables to represent a consumer’s age. The binned age variable is represented in the data set as six age cohorts. Each consumer is assigned to an age cohort based on their years since birth. The six cohorts include: 0-5 years old, 6-12, 13-17, 18-21, 22-50, and 51+. The cohorts are established based on the amount of financial support typically required during a particular life phase.
The 0-5 cohort (preschool age) has the fewest needs and requires the least amount of funding. For the 6-12 cohort (elementary school age) and 13-17 (high school age), a number of needed services are provided by schools. The 18-21 cohort is typically in a transition phase as the consumers begin moving out from their parents’ homes into community centers or living on their own. The majority of those in the 22-50 cohort no longer live with their parents but may still receive some support from their family. Those in the 51+ cohort have the most needs and require the most amount of funding because they are living on their own or in community centers and often have no living parents.
Gender is included in the data set as another variable to consider because it is an attribute on which many discrimination cases are based.
Expenditures variable represents the annual expenditures the State spends on each consumer in supporting these individuals and their families. It is important that students realize this is the amount each consumer receives from the State. Expenditures include services such as: respite for their families, psychological services, medical expenses, transportation, and costs related to housing such as rent (especially for adult consumers living outside their parent’s home).
Ethnicity is the key demographic variable in the data set as it pertains to the case. Eight ethnic groups are represented in the data set. These groups reflect the demographic profile of the State of California. Our key area of interest will become Hispanic and White, non-Hispanic comparisons.
Questions for Discrimination
Average Expenditures
- What is the average of expenditures for: (a) all males vs. all females,
- all Hispanics and all White, non-Hispanics,
Placeholder (you should not see this)
- all 22-50 year olds, The average expenditure for 22 to 50 year old clients is 40,209.28 dollars.
- all male, White non-Hispanics, The average expenditure for male and White not Hispanic clients is 24,573.80 dollars.
- all Asian, 22-50 year olds? The average expenditure for Asian 22 to 50 year old clients is 39,580.52 dollars.
Median Expenditures
- What is the median of expenditures for:
- all males vs. all females, The median expenditure for female clients is 6,400 dollars and the median expenditure for male clients is 7,219 dollars; the male median is about 12.5 percent larger than the female median.
- all Hispanics and all White, non-Hispanics, The median expenditure for Hispanic clients is 3,952 dollars and the median expenditure for White not Hispanic clients is 15,718 dollars. This difference is large.
- all 13-17 year olds, The median expenditure for 13 to 17 year old clients is 3,952 dollars. Note the similarity with the above.
- all male, White non-Hispanics, The median expenditure for White not Hispanic male clients is 27,390.50 dollars.
- all Asian, 13-17 year olds? The median expenditure for 13 to 17 year old Asian clients is 3,628.50 dollars.
Middle 50 Percent
The middle 50% of expenditures
- What is the range of the middle 50% of expenditures for: (a) all males vs. all females, The middle fifty percent of expenditures for female clients ranges from 2872.50 to 39,487.50 dollars and for male clients ranges from 2,954 to 37,201 dollars. This range, for males, is entirely contained in the range for females.
- all Hispanics and all White, non-Hispanics, The middle fifty percent of expenditures for Hispanic clients ranges from 2331.25 to 10,292.50 dollars and for White not Hispanic clients ranges from 3,977 to 43,134 dollars.
- all 13-17 year olds, The middle fifty percent of expenditures for 13 to 17 year old clients ranges from 3,306.50 to 4,665.50 dollars. Expenditures seem to balloon for adults; we can roughly compare this range to that in subpart (e).
- all male, White non-Hispanics, and The middle fifty percent of expenditures for male and White not Hispanic clients ranges from 4195.25 to 40,817.50 dollars.
- all Asian, 18-21 year olds? The middle fifty percent of expenditures for clients 18 to 21 years of age and Asian ranges from 7683 to 11,282 dollars.
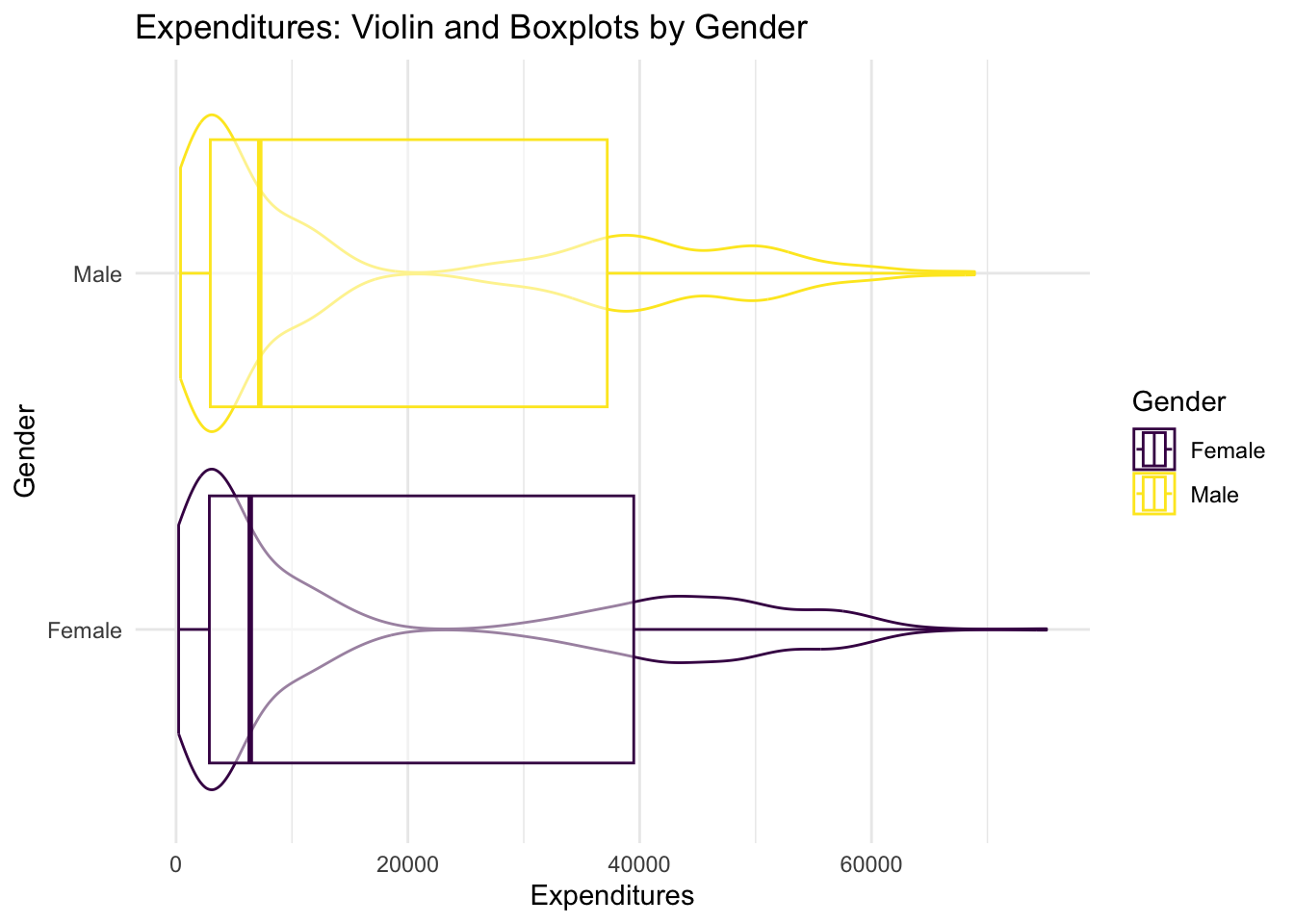
- Does discrimination in expenditures exist? There are two relevant potential forms of actionable discrimination: gender and ethnicity. Evaluate these two questions with the appropriate pivot table equivalent defined for each.
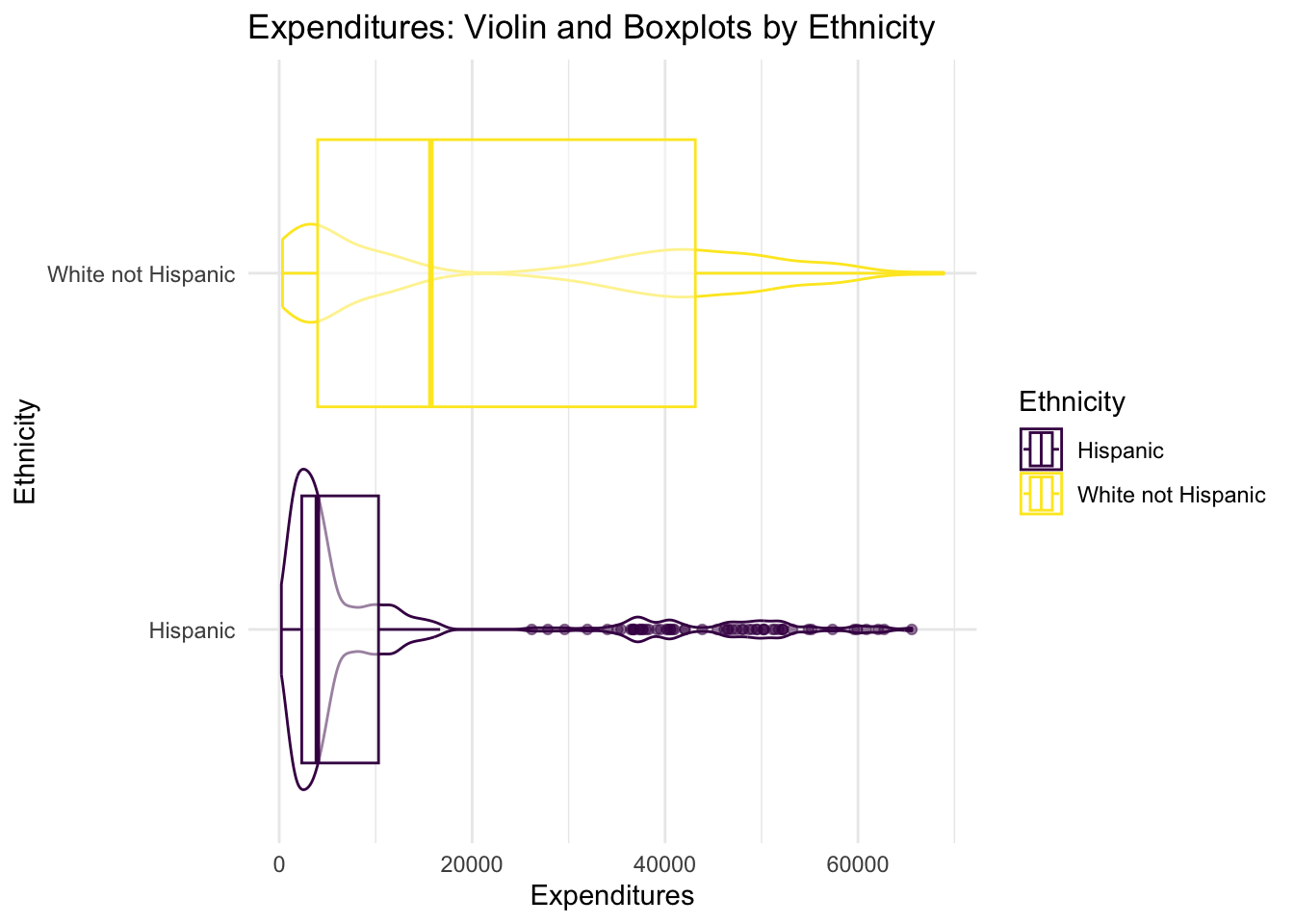
Not in gender, perhaps in ethnicity, where there is wide disparity..
- It is claimed that there are important disparities between Hispanic and White, not Hispanic. Is this true? Filter only Hispanics and White, not Hispanic. 6. After filtering only Hispanics and White, not Hispanic, compare the two groups by Age Cohort. What seems to be going on?
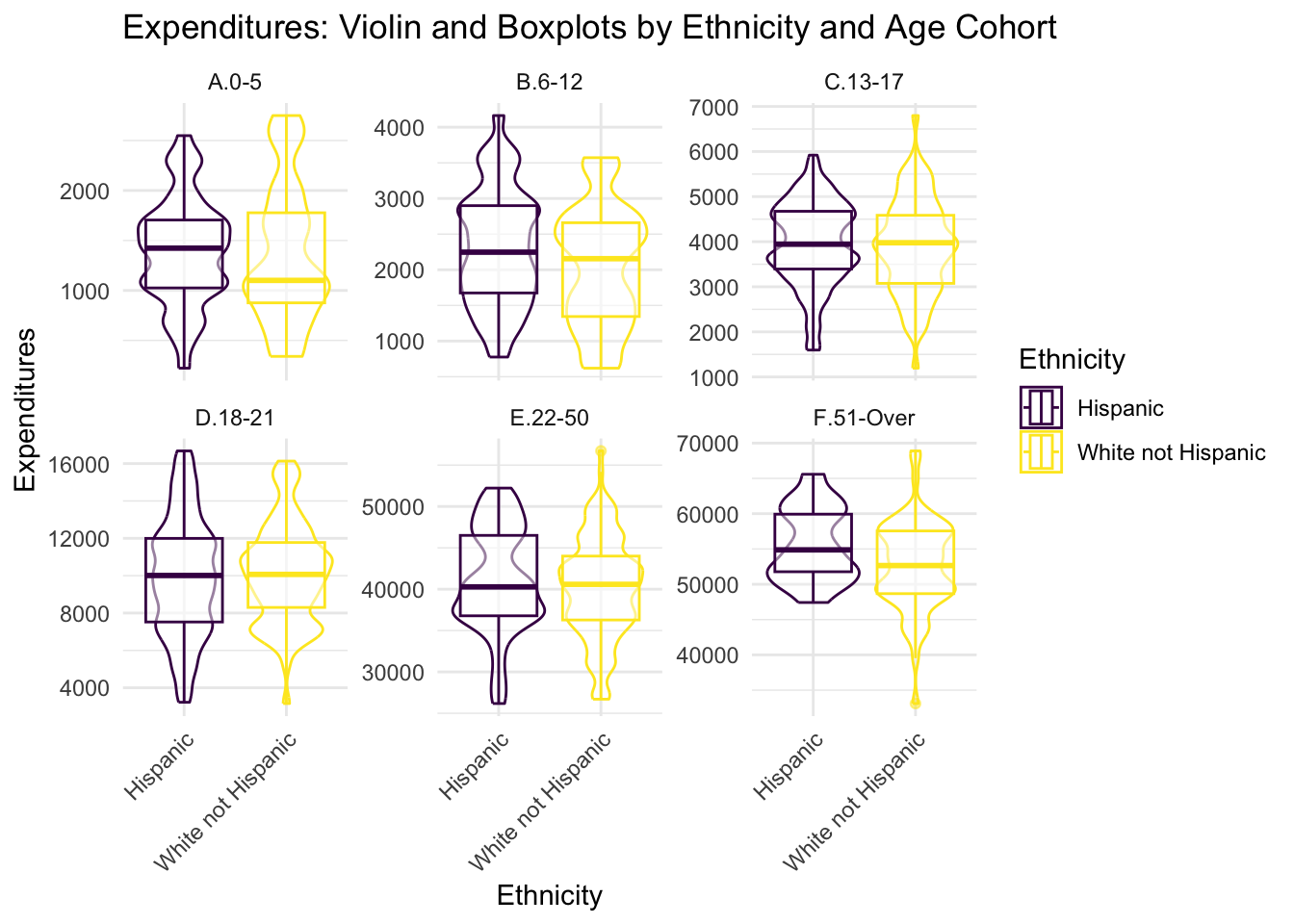
The apparent disparities seem to be accounted for by a different underlying age distribution among the two groups as the within age group comparisons show no obvious differences.
Consider the following additional issues keeping in mind that the data are a random sample from a broader population. (1) What is the relationship between age cohort and ethnicity for the comparison of White and Hispanic? (2) Are expenditures different by age cohorts? (3) How do the previous two answers interact to influence claims of discrimination?
In the right column above, there are far more Hispanic than White not Hispanic clients in the age cohorts under the age of 21, but in the older cohorts, this trend reverses and the vast majority of clients are White not Hispanic. When we note that expenditures are related to age, the apparent discrepancy in expenditures is to be expected to result from this distribution of ages among clients of varying ethnicities.
Berkeley Discrimination
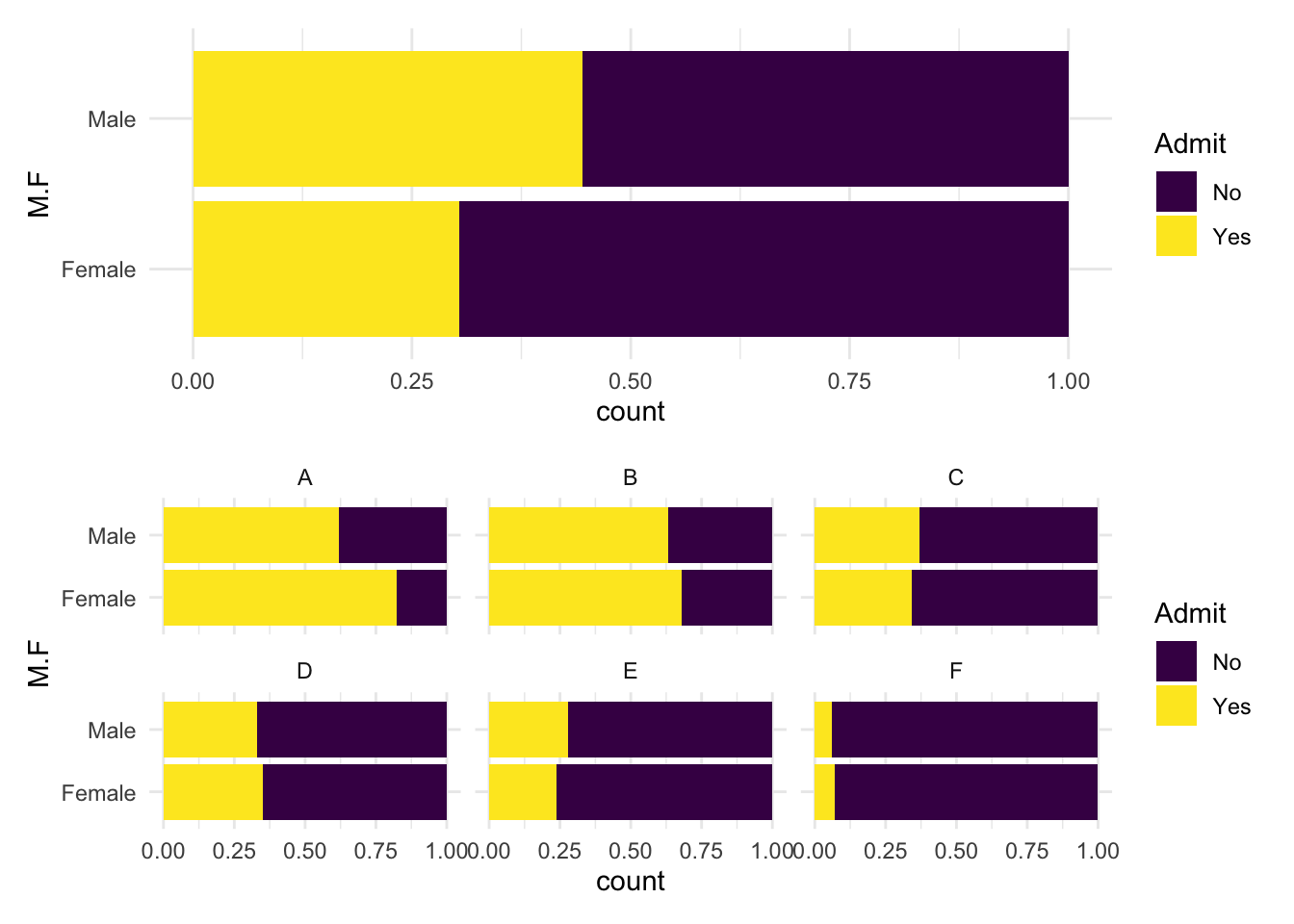
Is there evidence of sex bias in admission practices? Data on admissions to the University of California at Berkeley graduate programs in six departments are presented for the population of applicants. Admit measures whether or not the applicant was admitted; M.F measures the gender of the applicant; Dept measures the department in a classification ranging from A to F.
- Provide a table of M.F and Admit.
Cross-tabs
Data : UCBAdmit
Variables: M.F, Admit
Null hyp.: there is no association between M.F and Admit
Alt. hyp.: there is an association between M.F and Admit
Observed:
Admit
M.F No Yes Total
Female 1,278 557 1,835
Male 1,493 1,198 2,691
Total 2,771 1,755 4,526
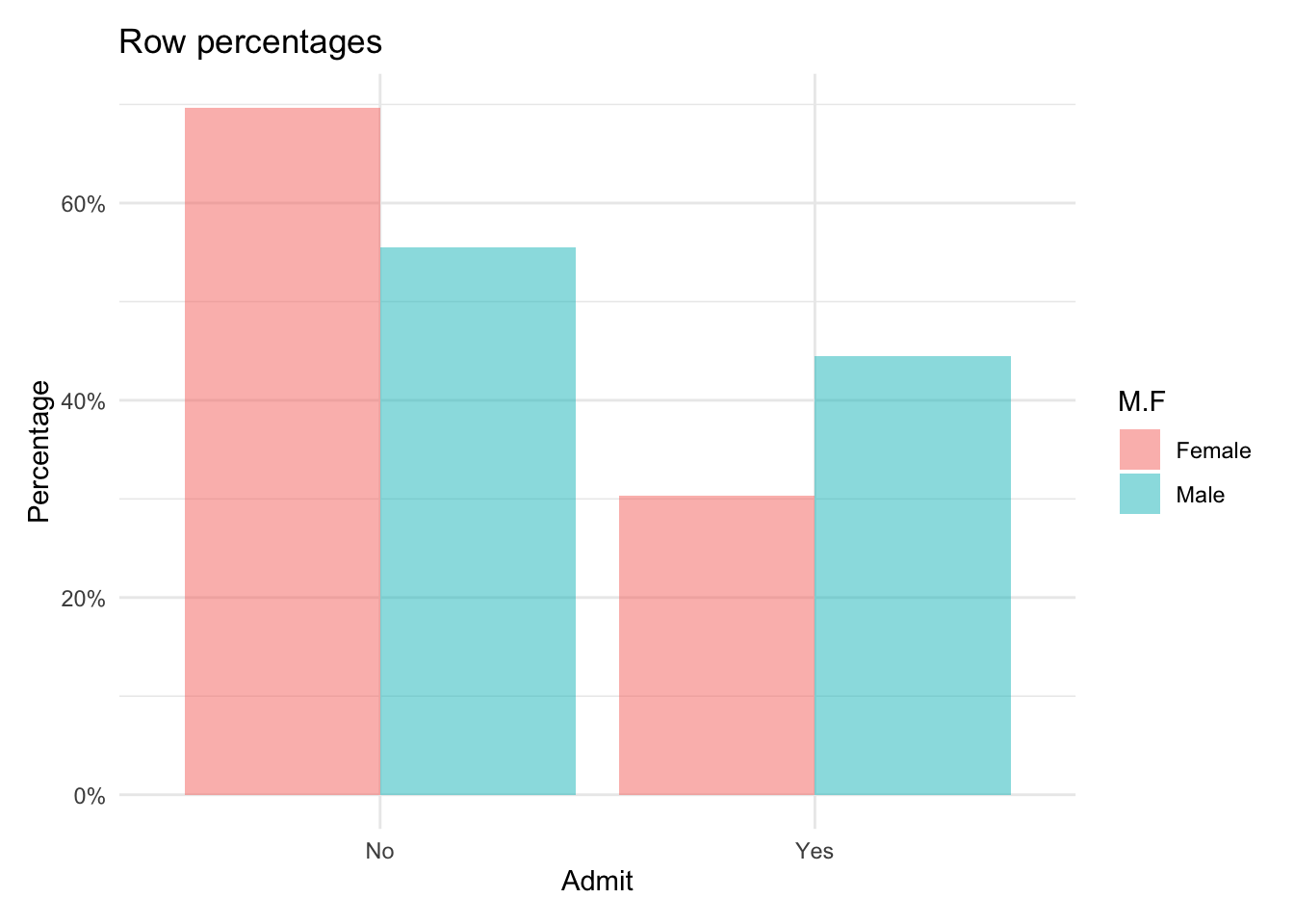
Row percentages:
Admit
M.F No Yes Total
Female 0.70 0.30 1
Male 0.55 0.45 1
Total 0.61 0.39 1
Chi-squared: 92.205 df(1), p.value < .001
0.0 % of cells have expected values below 5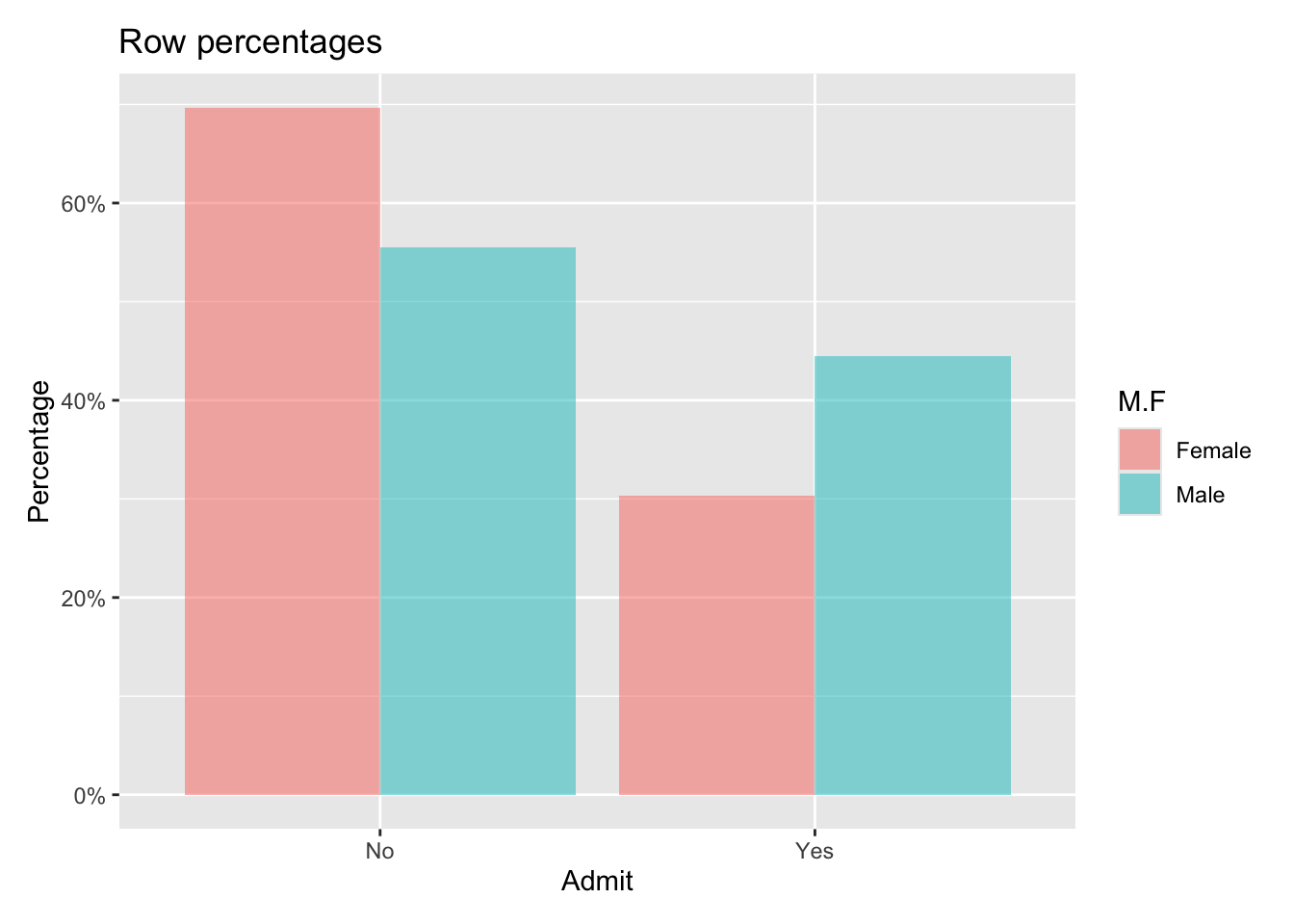
- Provide the two relevant tables of conditional probabilities for that table.
Some questions….
Some questions….
- Are men and women admitted to graduate programs at the same rate?
No. Women have a 0.3 probability of admission while men have a 0.45 probability of admission.
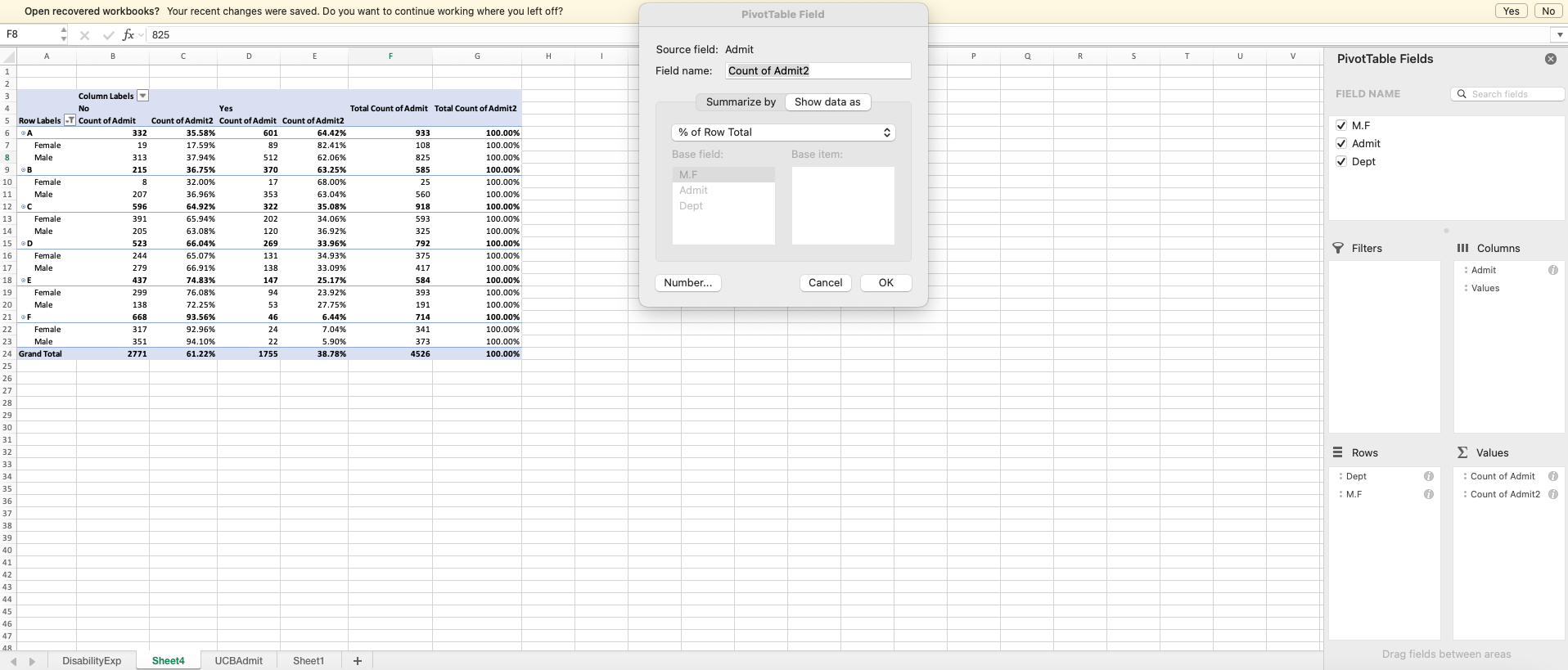
- Display and tabulate applications by department.
Results
Cross-tabs
Data : UCBAdmit
Filter : Dept=='A'
Variables: M.F, Admit
Null hyp.: there is no association between M.F and Admit
Alt. hyp.: there is an association between M.F and Admit
Observed:
Admit
M.F No Yes Total
Female 19 89 108
Male 313 512 825
Total 332 601 933
Row percentages:
Admit
M.F No Yes Total
Female 0.18 0.82 1
Male 0.38 0.62 1
Total 0.36 0.64 1
Chi-squared: 17.248 df(1), p.value < .001
0.0 % of cells have expected values below 5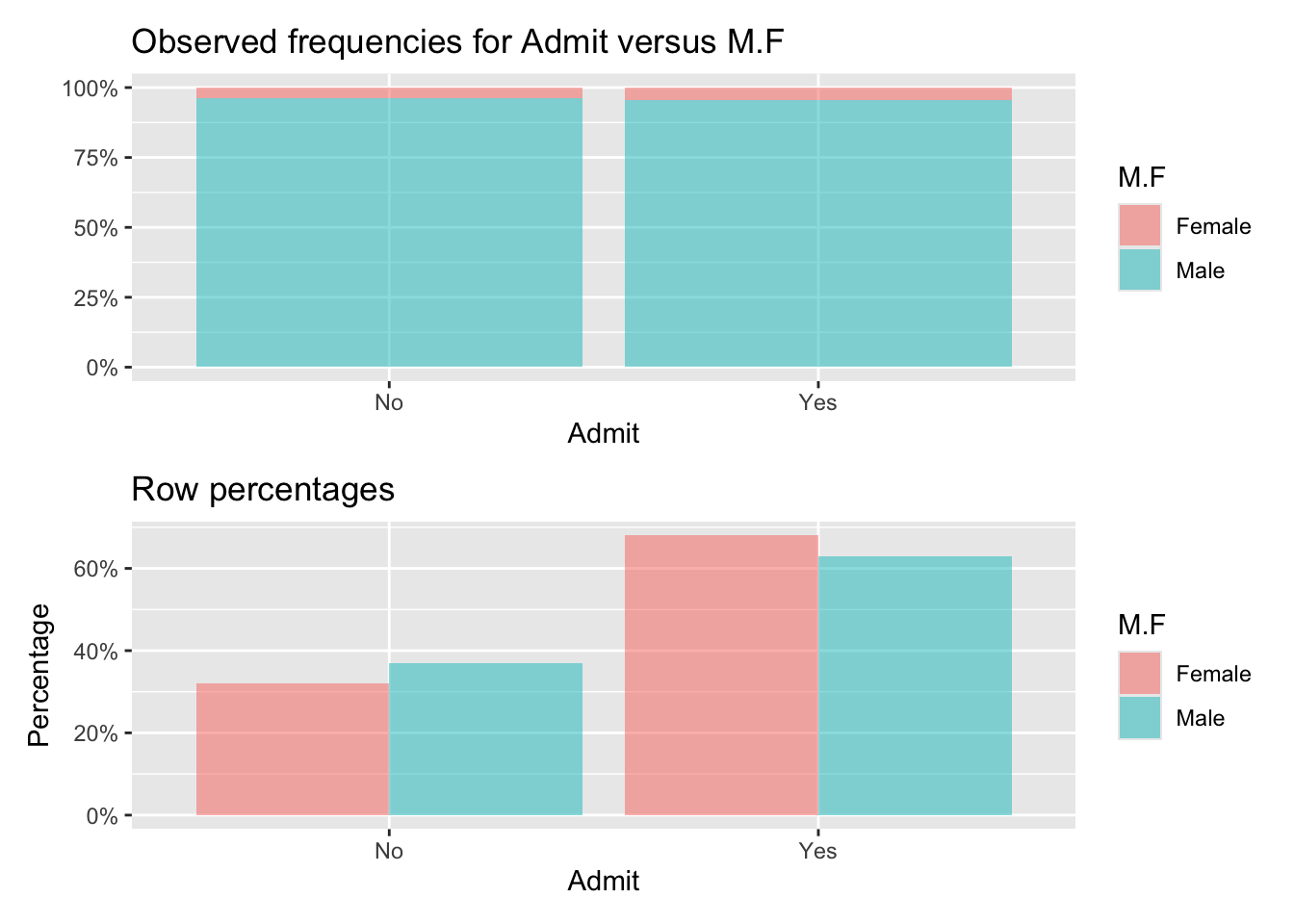
Cross-tabs
Data : UCBAdmit
Filter : Dept=='B'
Variables: M.F, Admit
Null hyp.: there is no association between M.F and Admit
Alt. hyp.: there is an association between M.F and Admit
Observed:
Admit
M.F No Yes Total
Female 8 17 25
Male 207 353 560
Total 215 370 585
Row percentages:
Admit
M.F No Yes Total
Female 0.32 0.68 1
Male 0.37 0.63 1
Total 0.37 0.63 1
Chi-squared: 0.254 df(1), p.value 0.614
0.0 % of cells have expected values below 5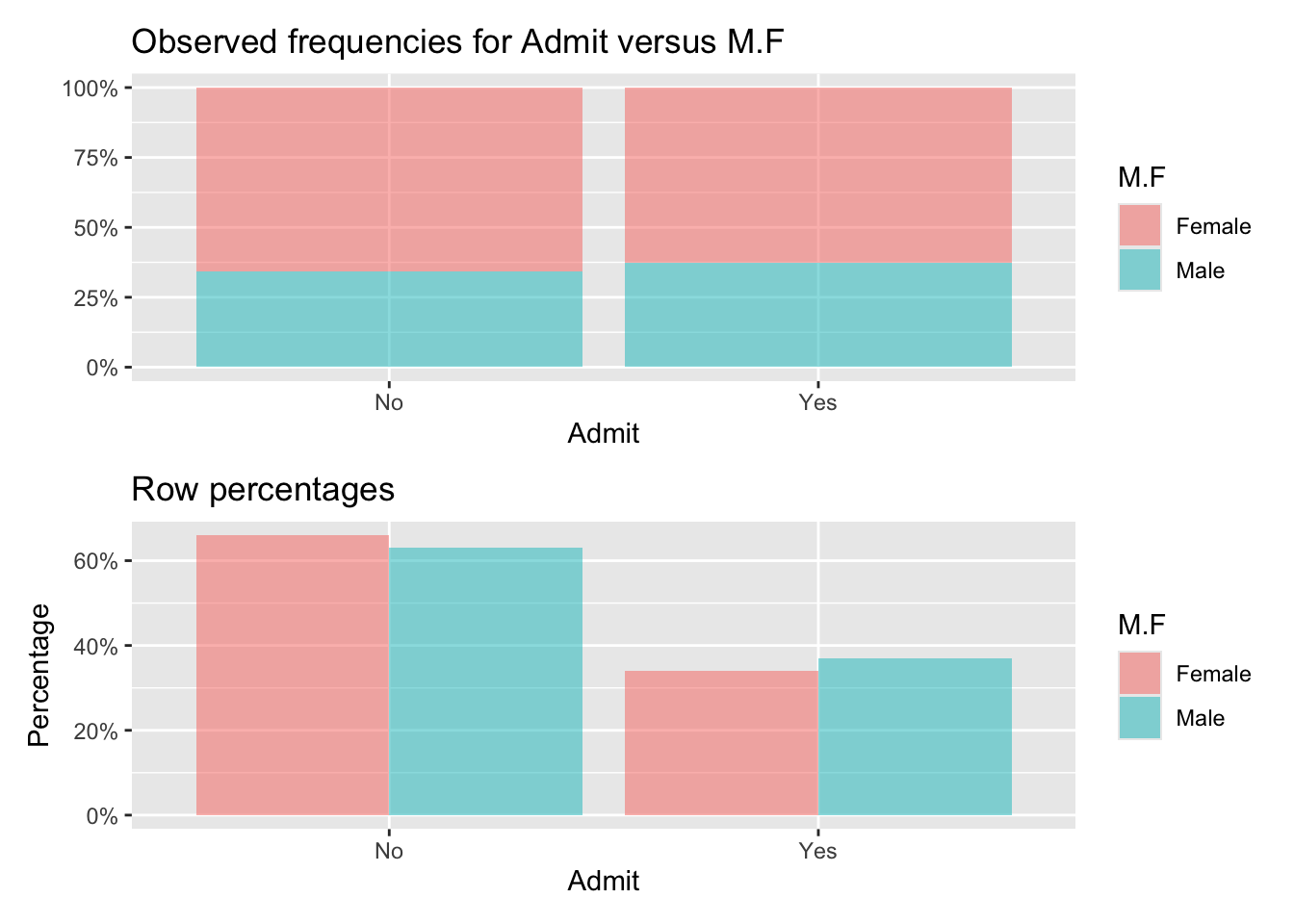
Cross-tabs
Data : UCBAdmit
Filter : Dept=='C'
Variables: M.F, Admit
Null hyp.: there is no association between M.F and Admit
Alt. hyp.: there is an association between M.F and Admit
Observed:
Admit
M.F No Yes Total
Female 391 202 593
Male 205 120 325
Total 596 322 918
Row percentages:
Admit
M.F No Yes Total
Female 0.66 0.34 1
Male 0.63 0.37 1
Total 0.65 0.35 1
Chi-squared: 0.754 df(1), p.value 0.385
0.0 % of cells have expected values below 5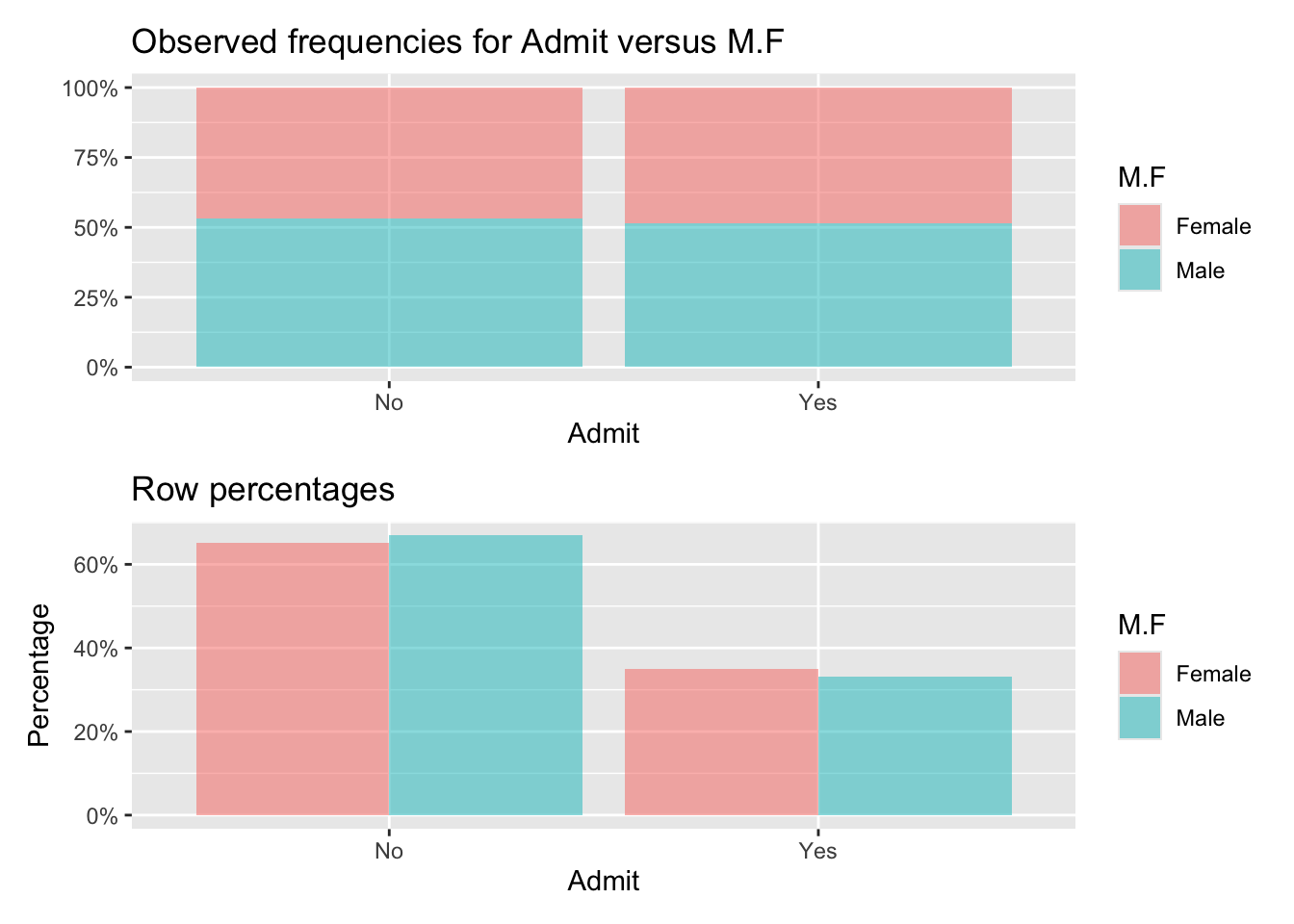
Cross-tabs
Data : UCBAdmit
Filter : Dept=='D'
Variables: M.F, Admit
Null hyp.: there is no association between M.F and Admit
Alt. hyp.: there is an association between M.F and Admit
Observed:
Admit
M.F No Yes Total
Female 244 131 375
Male 279 138 417
Total 523 269 792
Row percentages:
Admit
M.F No Yes Total
Female 0.65 0.35 1
Male 0.67 0.33 1
Total 0.66 0.34 1
Chi-squared: 0.298 df(1), p.value 0.585
0.0 % of cells have expected values below 5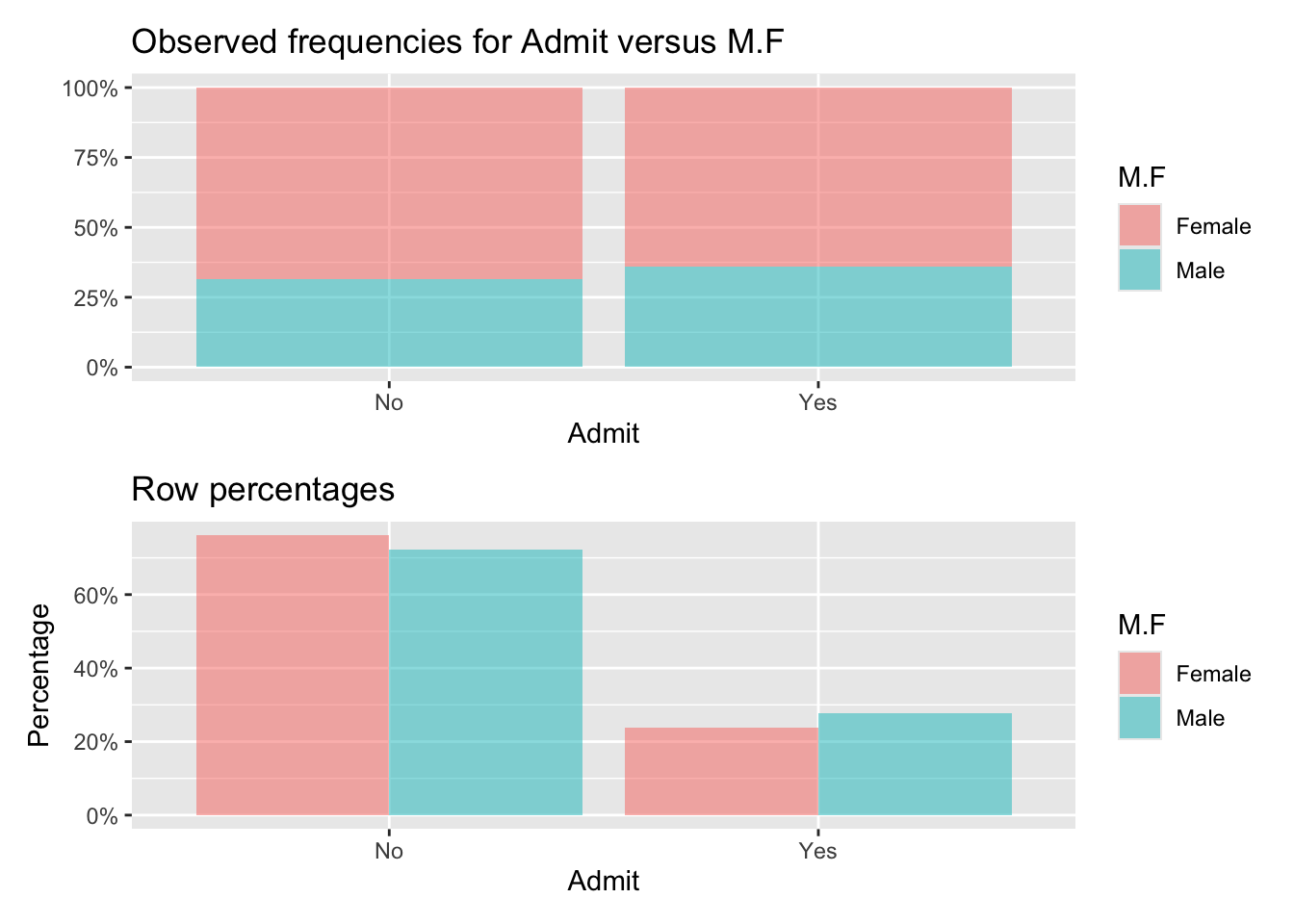
Cross-tabs
Data : UCBAdmit
Filter : Dept=='E'
Variables: M.F, Admit
Null hyp.: there is no association between M.F and Admit
Alt. hyp.: there is an association between M.F and Admit
Observed:
Admit
M.F No Yes Total
Female 299 94 393
Male 138 53 191
Total 437 147 584
Row percentages:
Admit
M.F No Yes Total
Female 0.76 0.24 1
Male 0.72 0.28 1
Total 0.75 0.25 1
Chi-squared: 1.001 df(1), p.value 0.317
0.0 % of cells have expected values below 5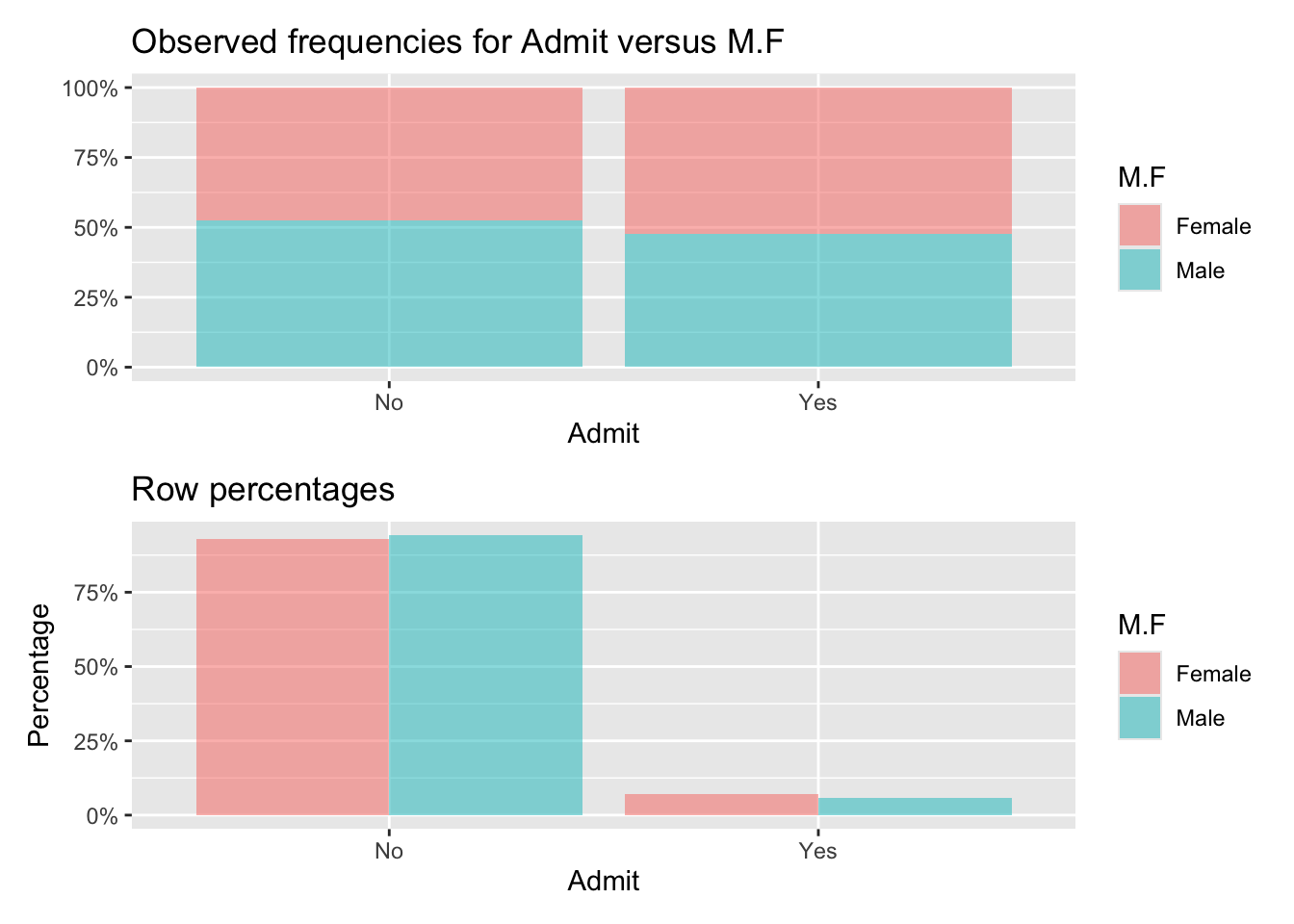
Cross-tabs
Data : UCBAdmit
Filter : Dept=='F'
Variables: M.F, Admit
Null hyp.: there is no association between M.F and Admit
Alt. hyp.: there is an association between M.F and Admit
Observed:
Admit
M.F No Yes Total
Female 317 24 341
Male 351 22 373
Total 668 46 714
Row percentages:
Admit
M.F No Yes Total
Female 0.93 0.07 1
Male 0.94 0.06 1
Total 0.94 0.06 1
Chi-squared: 0.384 df(1), p.value 0.535
0.0 % of cells have expected values below 5- Do any departments show differences in admissions rates by gender?
Not substantial differences and not systematically favoring either gender.
- Discuss 1 and 2 in light of claims of discrimination.
Women and men apply to different mixes of departments and it happens that women tended toward those with lower admission rates. However, within any department, there is little evidence of significant disparity. The graphic below shows the raw counts of male and female applicants by admission status. If departments differ in their underlying probability of admission and in their candidate pools, then gender discrepancies can result from the choices of the various genders rather than the genders of the various decisions.
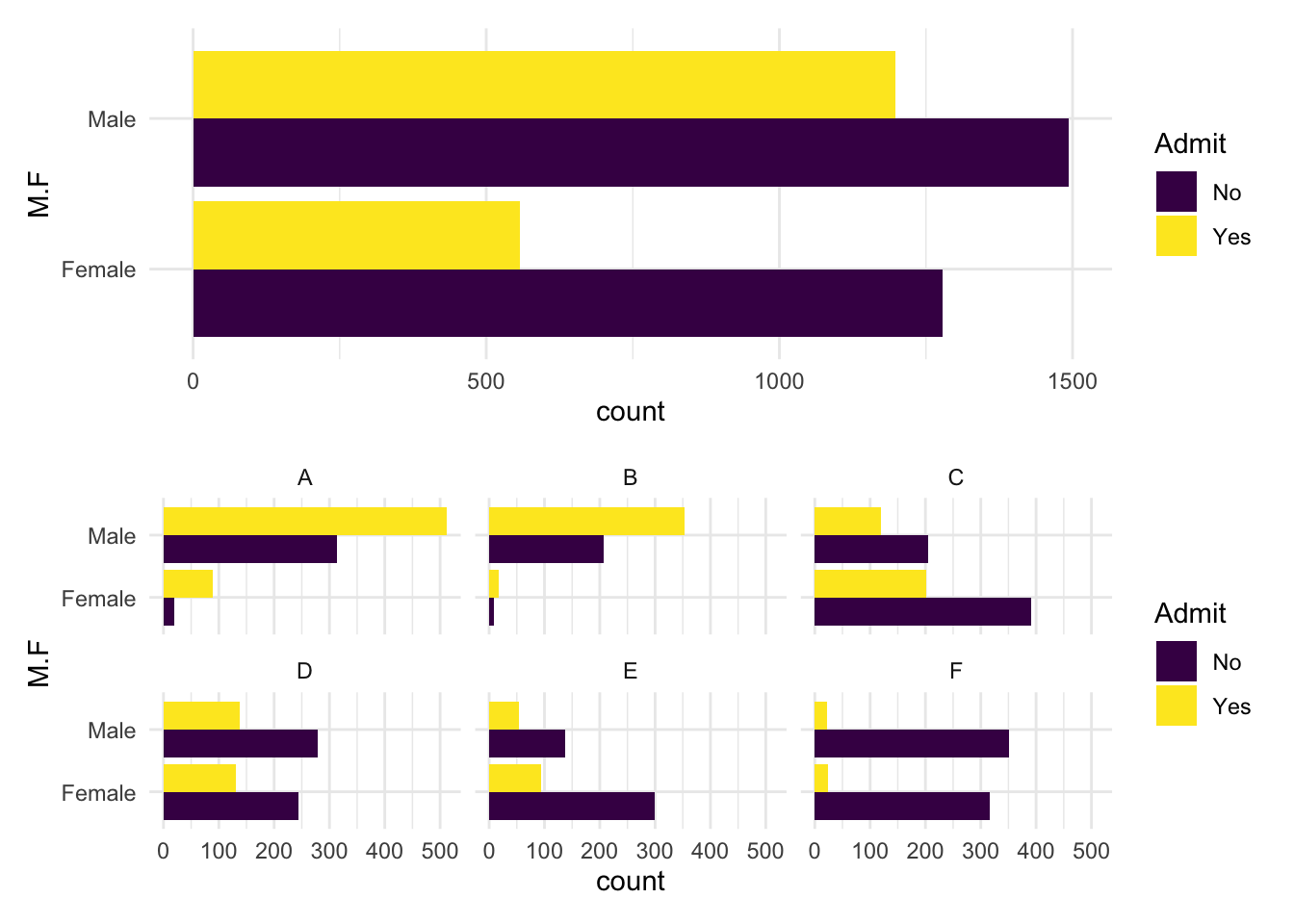
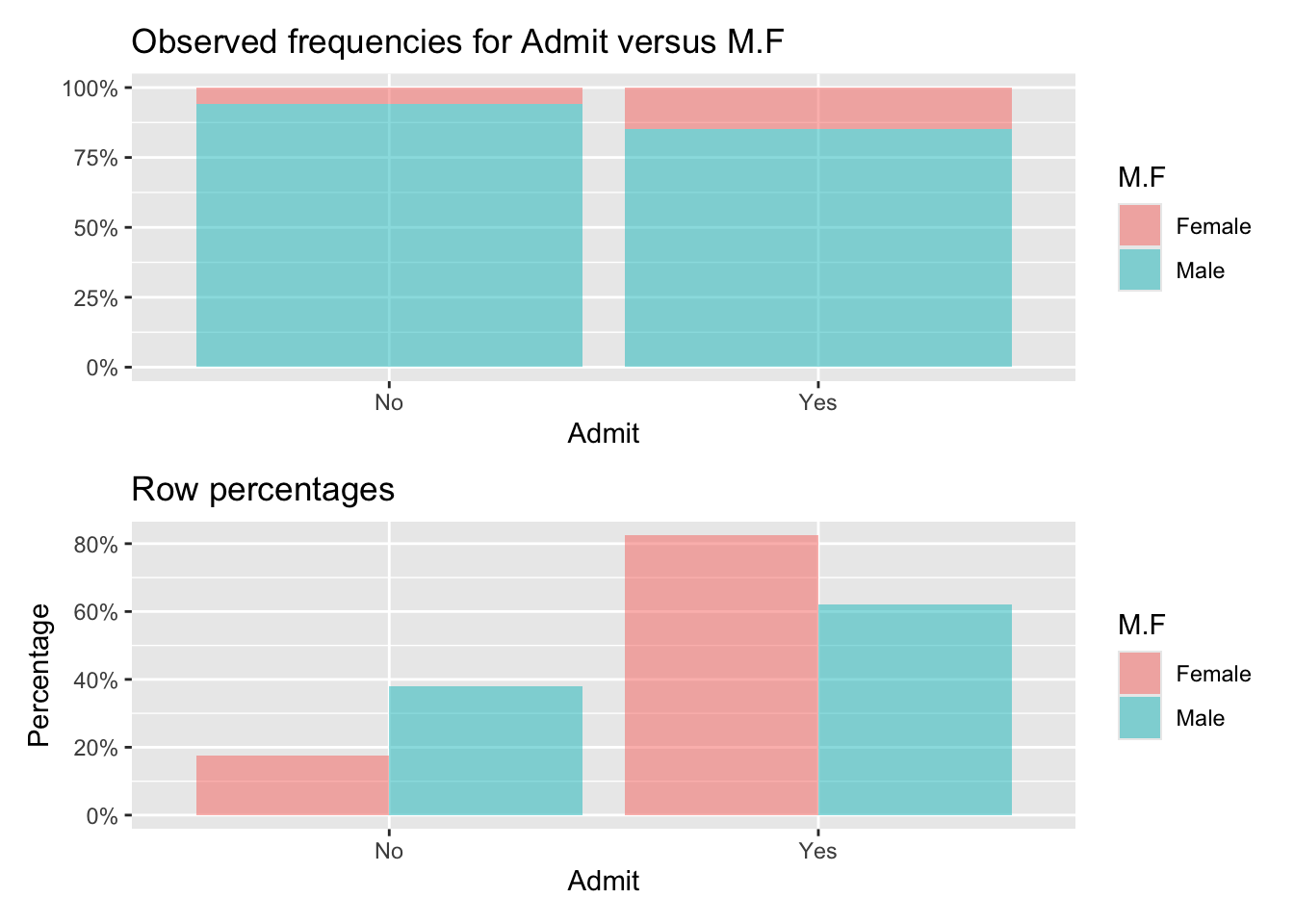
- Provide a graphic that showcases the apparent disparities and a graphic that dispels them that combines all three dimensions of the table.
The top panel showcases the aggregate disparity: 45% vs. 30%.
The bottom panel shows that in almost all departments, women are admitted at a higher rate than men except in Deparments C and E and the differences in those departments are small.