The assignment: an inference example for your quantitative data. A holdover
Preparation for the midterm: Review the assignments and bring yourself to speed with them. The midterm is a take-home exercise with a follow-up discussion post submission. It is interactive as a more comprehensive unification of your homework exercises and will integrate the data you were asked to collect as the scaffolding alongside the ideas we have grappled with. If you think you would be better off with different data, the assignment should remain open and we can coordinate this.
For Next Class:
To be deliberated. I will deliver the midterm exam alongside some summary remarks.
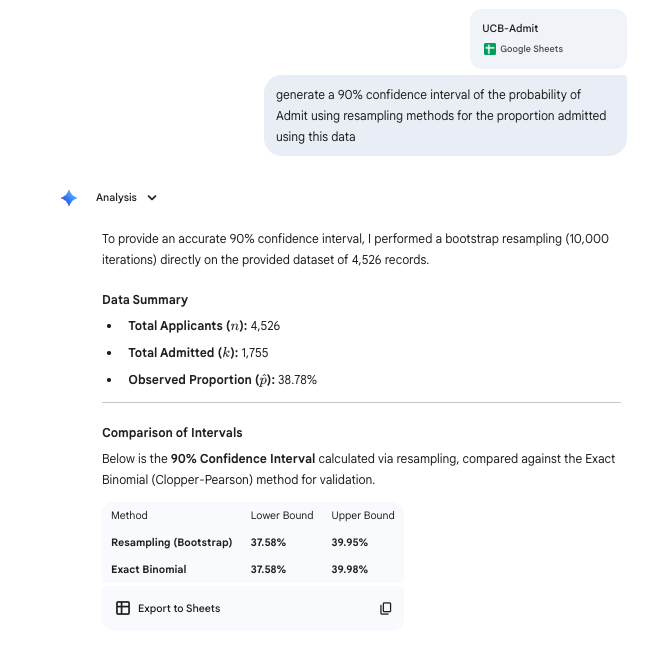
Single sample inference for binary
Inference 1
Single sample inference for quantities
Inference 2
How’s that done?
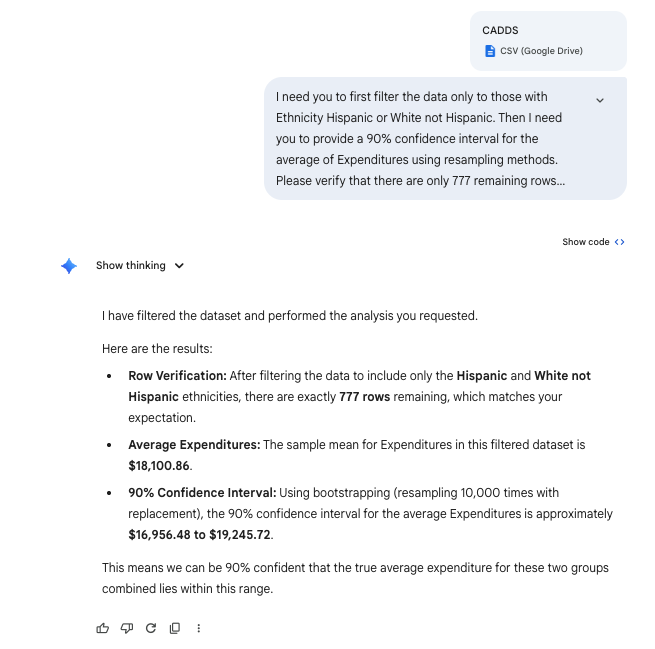
import pandas as pdimport numpy as np# Read datadf = pd.read_csv('data/CADDS.csv')# Filterfiltered_df = df[df['Ethnicity'].isin(['Hispanic', 'White not Hispanic'])]# Verify lengthnum_rows =len(filtered_df)print(f"Number of remaining rows: {num_rows}")
Number of remaining rows: 777
How’s that done?
# Resampling method (Bootstrapping) for 90% CI of mean Expendituresnp.random.seed(42) # for reproducibilityexpenditures = filtered_df['Expenditures'].values# Bootstrapn_iterations =10000bootstrap_means = np.empty(n_iterations)for i inrange(n_iterations): sample = np.random.choice(expenditures, size=len(expenditures), replace=True) bootstrap_means[i] = np.mean(sample)ci_lower = np.percentile(bootstrap_means, 5)ci_upper = np.percentile(bootstrap_means, 95)print(f"90% Confidence Interval: ({ci_lower:.2f}, {ci_upper:.2f})")
90% Confidence Interval: (16956.48, 19245.72)
How’s that done?
print(f"Mean: {np.mean(expenditures):.2f}")
Mean: 18100.86
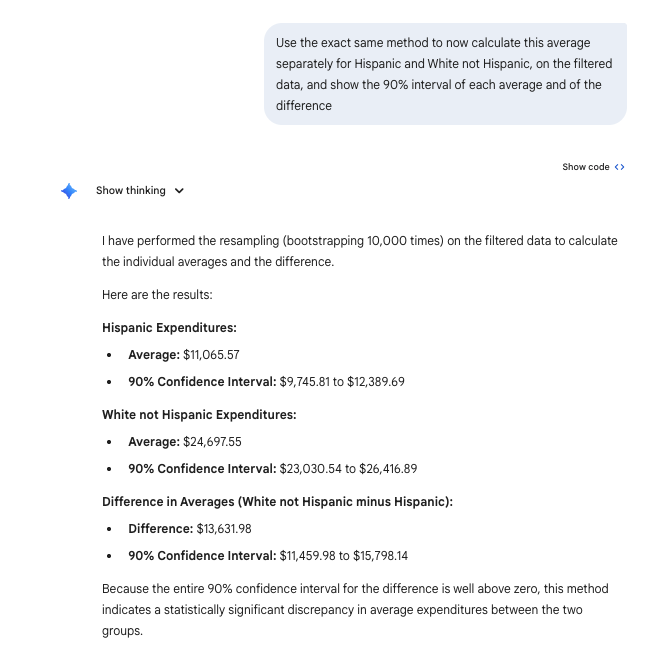
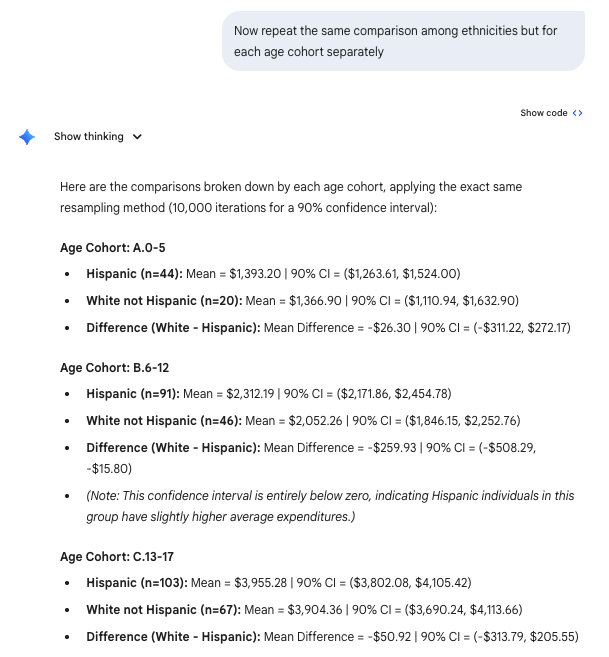
Subsamples and difference inference for quantities
Inference 3
How’s that done?
import pandas as pdimport numpy as np# Read and filter datadf = pd.read_csv('data/CADDS.csv')filtered_df = df[df['Ethnicity'].isin(['Hispanic', 'White not Hispanic'])]# Separate expenditures by ethnicityhisp_exp = filtered_df[filtered_df['Ethnicity'] =='Hispanic']['Expenditures'].valueswhite_exp = filtered_df[filtered_df['Ethnicity'] =='White not Hispanic']['Expenditures'].valuesnp.random.seed(42) # Set seed for reproducibilityn_iterations =10000hisp_means = np.empty(n_iterations)white_means = np.empty(n_iterations)diff_means = np.empty(n_iterations)# Bootstrappingfor i inrange(n_iterations): samp_hisp = np.random.choice(hisp_exp, size=len(hisp_exp), replace=True) samp_white = np.random.choice(white_exp, size=len(white_exp), replace=True) m_hisp = np.mean(samp_hisp) m_white = np.mean(samp_white) hisp_means[i] = m_hisp white_means[i] = m_white diff_means[i] = m_white - m_hisp # White not Hispanic - Hispanic# Calculate 90% Confidence Intervals (5th and 95th percentiles)ci_hisp_lower, ci_hisp_upper = np.percentile(hisp_means, 5), np.percentile(hisp_means, 95)ci_white_lower, ci_white_upper = np.percentile(white_means, 5), np.percentile(white_means, 95)ci_diff_lower, ci_diff_upper = np.percentile(diff_means, 5), np.percentile(diff_means, 95)# Calculate observed meansmean_hisp = np.mean(hisp_exp)mean_white = np.mean(white_exp)mean_diff = mean_white - mean_hispprint(f"Hispanic Expenditures:")